| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- people analytics
- 회귀분석
- LDA Topic Modeling
- Workforce Analytics
- 자기소개서 스크리닝
- Talent Analytics
- HR 데이터 분석
- ChatGPT
- HR Analytics
- HR Anlaytics
- 피플 애널리틱스
- 성장혼합모형
- 데이터분석
- PA201
- HR
- Text mining
- Pa
- HR데이터
- HRA
- PA 미래
- survival analytics
- HR대시보드
- Jobplanet
- 하나만 쓰자..
- 다항로지스틱회귀분석
- 인사데이터
- 유사도분석
- 태그도 많이 치는거 힘들다..
- 채용 대시보드
- HR 애널리틱스
- Today
- Total
People-Analytics201
채용 적합도 파악을 위한 다중 회귀 분석 본문
본 포스팅은 PA201 구성원 "김김김"님에 의해 작성된 글입니다.
[Part 1] 개요 및 목적
지원서 항목 외 채용 과정에서 드러나는 지원자에 대한 부가적인 정보들이 있음. 예를 들어, '저는 술자리를 매우 좋아하고 즐깁니다.', ' 저는 사회적으로 다양한 활동을 주도하고 있고, 많은 사람들과 친분관계를 유지하고 있는 것이 장점입니다.' 등의 것들임. 최고의 인재를 가려내기 위해선 작은 단서들도 소홀히 할 수 없기 때문에, 이런 부가적인 정보들과 채용 적합도의 관계를 분석하는 모델을 만들고자 함.
분석 모델링 절차

출처 : www.eduatoz.kr
1. 모델링 마트 설계
- 한국노동패널조사 : 1~24차년도 자료 다운
- 데이터 전처리 : 결측값 포함 행 제거
2. 탐색적 분석
- 유의 변수 도출 : 통합 코드북 활용
- 독립변수(x) : (여부)흡연/음주 (만족도)여가 활동/주거 환경/가족 관계/사회적 친분 관계
- 종속변수(y) : 직무 만족도(5개 항목) 및 조직 몰입도(5개 항목) 평균 값 활용
3. 모델링
- 모형 후보 선정 :
독립변수(x) : 연속형(다수)
종속변수(y) : 연속형
⇒ 다중선형회귀분석
- 데이터 분할
: 샘플 갯수 12611개(샘플 갯수 충분)
⇒ 홀드 아웃(Hold Out)기법 선택 [Train:validation:test=75:0:25]
※ 참고
데이터가 충분하지 않을 경우 ⇒ 교차검증 K-Fold Cross Validation, Bootstrap
데이터가 한정적이면서, 정확한 예측이 필요(단, 느림) ⇒ 교차검증 LOOCV
- 회귀 모형의 가정이 성립하는지 확인
|
회귀 모형의 가정
|
설명
|
검증 방법
|
|
선형성
|
모형은 선형(linear)성을 가짐
|
예측값-잔차 비교
|
|
독립성
|
잔차와 독립변수의 값 관련 없음
|
Durbin-watson
|
|
정규성
|
잔차항이 정규분포를 이루어야 함
|
Normal Q-Q Plot
|
|
등분산성
|
잔차항들의 분포는 동일한 분산을 갖음
|
Scale-Location
|
|
비상관성
|
잔차들끼리 상관이 없어야 함
|
①. 선형성 : 예측값(fitted) vs. 잔차(residual). 잔차(빨간 실선)이 점선과 비슷해야 함
(크게 차이나면, 예측값에 따라 잔차가 크게 차이남. 선형성 없음)

②. 독립성 : Durbin-Watson 결과 값이 1.5~2.5 사이면 독립으로 판단
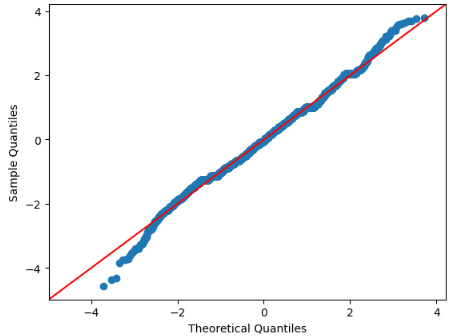
③. 정규성 : Q-Q Plot. 잔차들이 대각선 상에 있어야 이상적
x축 -2이하로는 이탈하여도 ok, -1부터 이탈시 정규성X
④. 등분산성 : 예측값 vs. 표준화 잔차. 빨간색 선이 수평에 가까울수록 등분산

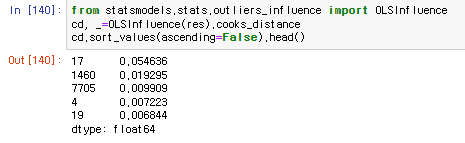
⑤. Outlier : Leverage와 잔차(residual)가 동시에 큰 데이터
Cook's distance 계산 ⇒ 1초과시 영향점(influence points)로 판별
- 모형 학습 및 결과
: OLS(Ordinary Least Squares) 결정론적 선형 회귀 방법. statsmodels 모듈 사용
|
※ 참고
|
회귀 계수 확인
|
모형 평가 지표 확인
|
입력 변수 유의성 검정 p-value 확인
|
|
sklearn.linear_model
|
o
|
o
|
x
|
|
statsmodels
|
o
|
o
|
o
|

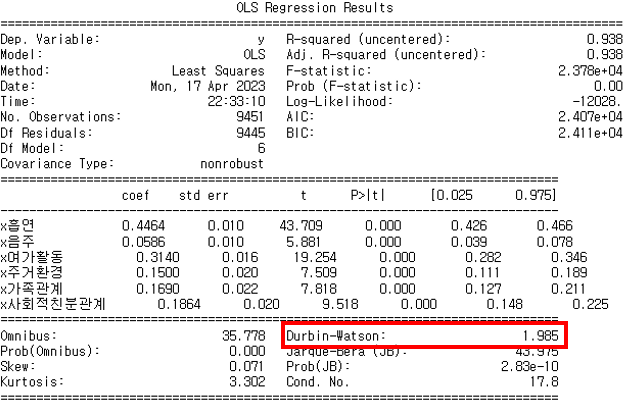
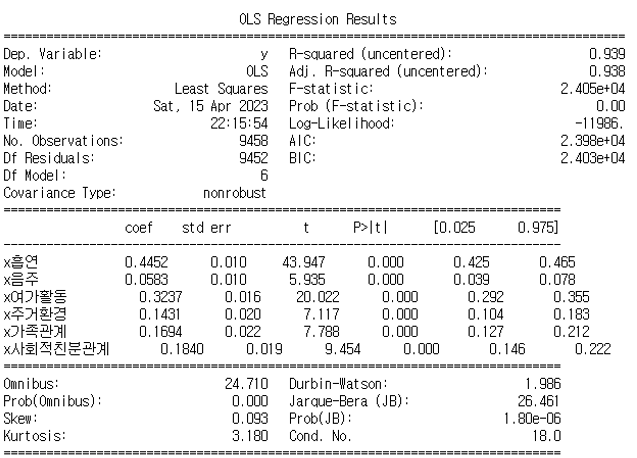
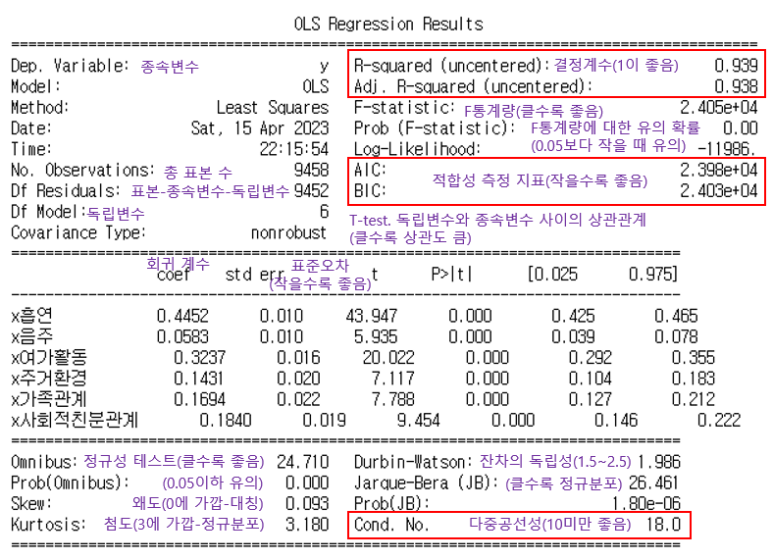
⇒ 결정계수 R-squared 0.939로 1에 매우 가까워 회귀방정식의 설명력이 높다고 판단
4. 성능 평가
- 평가 지표 기반 성능 평가
: OLS 회귀 모형 성능 결과(statsmodels.api의 summary 기능 활용)
⇒ 모델 성능이 매우 좋고, 회귀 계수들 또한 유의함
하지만 다중공선성이 있으며, AIC/BIC 값이 매우 크므로 독립 변수(x)들에 대한 재검토가 필요함
- 모형 학습 파라메타 조정 : 위의 평가 결과에 따라 다중공선성 해결이 필요
|
다중공선성 : 일부 독립변수(x)들이 서로 높은 상관관계가 있을 때 발생.
회귀 계수의 분산을 증가시켜 모델이 불안정해지고 해석을 어렵게 함 해결법 : 변수 축소(주성분 분석, 요인 분석, 다차원 척도법 등), 변수 제거,
Ridge/ Lasso/ Elastic Net 회귀 분석 활용, Mean Centering 등 |
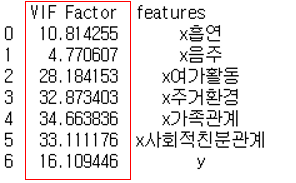
① 각 변수의 다중공선성 확인
: 독립변수(x) 별 VIF 측정 결과 대부분의 변수에 다중공선성이 존재함을 확인
② 주성분 분석
|
주성분 분석(PCA) : 여러 차원의 변수를 대표하는 새로운 차원의 주성분을 생성
|
: 주성분 결정
- Standard deviation : 분산이 클수록 설명력이 높음
(분산이 최대가 되는 축을 주성분의 축으로 결정)

- Proportion of Variance : 각 주성분(PC)들이 갖는 설명력의 비율
총 합이 70%~90%가 되는 주성분 개수를 선택

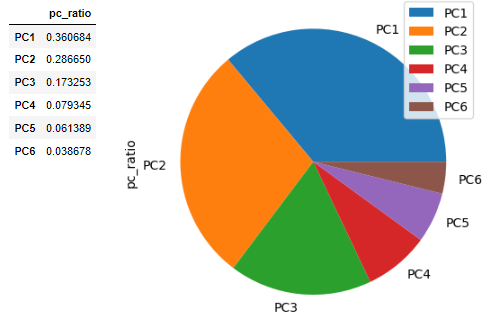
⇒ PC1, PC2, PC3 의 설명력 합은 약 80%(0.35+0.28+0.17=0.8)이므로
주성분의 개수는 3개. PC1~3 선택
③ 선택된 주성분 3개로 Dataset 재구성
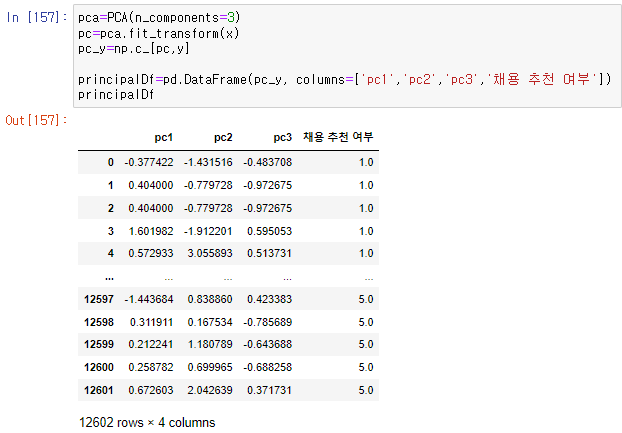
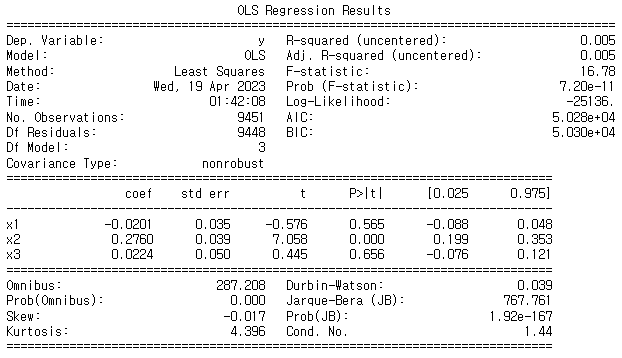
④ 주성분 분석 결과 반영하여 회귀 분석 실행
: 분석 결과 성능이 오히려 떨어졌으며, 전반적인 평가 지표들의 결과도 나빠졌음
(다중공선성이 존재하지만, 모형의 성능에 문제가 되는 수준이 아니었고
각 변수들의 역할이 모두 중요했기 때문일 거라는 추측)
⇒ 주성분 분석 결과는 반영하지 않고, 기존 분석 모델 그대로 활용
[Part 2]
개선 Point 1 : 결측값 처리 기법 적용
데이터 양이 충분하다 보니 결측값이 있는 샘플에 미련이 없어 삭제 처리 함(.dropna() 사용)
하지만 데이터 왜곡 유발 원인이 됨
⇒ 결측값 처리 기법 적용시 더 정확한 분석이 가능
- 결측값 처리 기법 별 적용 결과 비교
: Hot-deck 기법 적용시, 기존의 단순 제거 방식 대비 P-value 증가(0.938 -> 0.957)
|
기법
|
제거
(기존 분석)
|
특정 값으로 대체
|
선형 보간법
|
Hot-deck
|
|
Code 예시
|
.dropna()
|
df.fillna(2.5)
|
interpolate(method=
'linear',limit=5)
|
KNNImputer(~~)
|
|
기법 적용
후 P-value
|
0.938
|
0.923
|
0.943
|
0.957
|

개선 Point 2 : 성격이 다른 종속 변수를 구분하여 활용
분석에 사용한 종속변수(y)는 직무 만족도(5개 항목) 및 조직 몰입도(5개 항목)의 전체 평균.
하지만 직무 만족도 와 조직 몰입도 항목은 각각 다른 개념임을 뒤늦게 깨닳음
⇒ 종속변수를 2가지로 구분하여 각각 분석
- 종속 변수 구분 후 분석 결과
: 종속변수를 구분하여 각각에 대한 회귀 분석을 진행 함. 기존 분석 이상의 분석 결과를 보임
성격이 다른 변수를 섞지 않고 구분하였기 때문에 성능이 향상 된 것으로 추측
|
종속 변수(y)
|
직무 만족도 5개 항목 평균 값
|
조직 몰입도 5개 항목 평균 값
|
|
p-value
|
0.961
|
0.957
|
|
회귀 계수
|
x흡연 0.486251
x음주 0.035643
x여가활동 0.264377
x주거환경 0.122158
x가족관계 0.129504
x사회적친분관계 0.227875
|
x흡연 0.518257
x음주 0.037463
x여가활동 0.278633
x주거환경 0.131063
x가족관계 0.124754
x사회적친분관계 0.210669
|
개선 Point 3 : 적정 표본 수 계산
무료로 쉽게 얻을 수 있는 표본을 사용하여 분석하였기에 표본 수에 대한 고민이 없었음
표본은 많을수록 검정력(Power)가 커지지는 장점이 있음.
하지만 실무에선 표본의 수는 비용과 직결하기 때문에 적정 표본 수에 대한 파악이 필요함
⇒ 적정 표본 수 계산에 대한 방법을 알아 둘 필요가 있음
- 분석 기법 별 최소 표본 크기 산정
: 통계 기법에 따라 적정 표본 수가 달라지는데, 아래 문서(링크)에서 이에 대한 자세한 설명을
확인할 수 있음. 표본 크기 관련 국내 연구 실태도 소개되어 있어 흥미로움.
이를 좀 더 시간을 갖고 공부하여 파악하고자 함
|
|
느낀점
과제 수행에 앞서 이론 공부에 많은 시간을 할애하였는데, 분석에 대해 기존보다 깊게 알아가는 기회가 되었음.
기존에는 분석 기법의 종류와 실행법, 그리고 결정계수 확인을 통한 검증 정도만 알고 있었음.
변수 선택 기법, 데이터 불균형시 고려할 사항, 데이터 분할 기법, 모형 해석의 다양한 지표 등 새로운 개념들이 흥미로웠음.
AIC/BIC 지표도 낮춰 보고싶었으나 어려움이 있었고, Lidge/ Lasso/ Elastic Net 과 같은 정칙화 기법도 활용해보고 싶었으나 공부가 더 필요하다는것을 느꼈음. 다음엔 이런 부분까지 고려하여 분석하고 싶음.
'People Insight' 카테고리의 다른 글
| AI 영상면접기술을 활용한 채용 방식의 타당성 검토 (0) | 2023.05.20 |
|---|---|
| 인적성검사(역량검사)을 활용한 채용 PA (0) | 2023.05.07 |
| 제약업계 다양성 지표 활용 사례 (0) | 2023.05.05 |
| 성장혼합모형(GMM)을 적용한 채용 PA (0) | 2023.04.22 |
| 핵심인재 요인도출 (0) | 2023.04.22 |