| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- 성장혼합모형
- 피플 애널리틱스
- HR대시보드
- 데이터분석
- PA 미래
- HR 애널리틱스
- people analytics
- 회귀분석
- Workforce Analytics
- 채용 대시보드
- Jobplanet
- PA201
- 태그도 많이 치는거 힘들다..
- 유사도분석
- HRA
- LDA Topic Modeling
- 인사데이터
- HR데이터
- HR Anlaytics
- 하나만 쓰자..
- HR Analytics
- 다항로지스틱회귀분석
- HR
- HR 데이터 분석
- Pa
- Text mining
- survival analytics
- ChatGPT
- 자기소개서 스크리닝
- Talent Analytics
- Today
- Total
People-Analytics201
핵심인재 요인도출 본문
본 포스팅은 PA201구성원 ‘DH’님에 의해 작성된 글입니다.
개요
현재 HR업무 진행하며 주로 활용하는 DB가 인사고과(평가), 동료평가, 자격, 수상, 근무경력 외 인구통계학적 속성에 머물고 있다. 기업의 존속과 목표달성을 위하여 핵심인재의 관리와 유지는 매우 중요해지고 있으나 HR팀이나 PA팀 대부분 데이터를 분석할 때 협소한 접근방식을 취할 수밖에 없다. 그리고 이런 개인단위 분석 DB(특히 인사고과)를 토대로 직원에 대한 주요 의사결정(채용, 승진, 보직, 보상)이 이루어질 수밖에 없고, 일부 조직은 DB분석 없이 감과 경험으로 의사결정이 이루어지기도 할 것이다. 사내 산재되어 활용되지 않은 추가 DB가 무엇일지 고민하고 추가수집, 분석하여 모델링한다. 회귀분석 모델은 핵심인재가 갖추고 있는 요인 간의 상호관계를 도출하는데 도움이 되고, 모델의 성능이 우수할 경우 해당 요인들은 채용 상의 자소서 키워드, 인적성, 구조화면접 등에 활용 가능하겠으며 점진적으로 승진자추천모델, 석세션플랜 진단 등에 활용 기대한다.
가설
1. 핵심인재는 단기고과 우수자라기 보다는 장기근속 하면서 회사의 주요 부문에서 우수한 성과와 함께 리더십과 회사정책에 적극적 참여하는 적극성을 가진 직원일 것이다.
2. 사내 핵심이라고 일컬어지는 현재시점 주요 직책자와 우수직원의 리스트를 S등급으로 구분하고, 우수한 고과를 가졌더라도 징계가 있거나 조기퇴사한 인력의 리스트는 X등급, 지속적으로 성과가 좋지 않은 저성과자 C등급, 일반 직원리스트는 A등급으로 구분하여 이들 사이에는 구별되는 특성요인이 있을 것이다.
3. 핵심인재는 반드시 고평가자는 아닐 것이다.
데이터
데이터 소개
엑셀 형식 (sap추출, 5,340행, 28개 Features, 최근 15년, 퇴사자포함)

전처리
결측치 제거하고 2,390행 , 22열 작업
레이블인코딩(카테고리 피처를 숫자 값으로 변환)
[데이터 info]
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 2390 entries, 0 to 2389
Data columns (total 22 columns)
[features 설명]
| lab 인재등급 (target 값/종속) ★ |
| atn 재직여부 |
| age 나이 |
| sex 성별 |
| sta 입사구분 |
| prd 재직기간 |
| deg 최종학력 |
| ovs 해외대학출신 |
| dom 국내top대학 |
| tor 관광과출신 |
| asm 인사평가평균(10년) |
| asl 인사평가등급 |
| upm 상향평가평균(10년) |
| upl 상향평가등급 |
| pun 징계등급 |
| hom 재택근무기록 |
| rel 휴직구분 |
| rep 휴직기간 |
| glb 글로벌엑스퍼트 |
| for 외국어능력구분(다수언어포함) |
| rew 포상등급 |
| imp 자기개발기록 |
모델링
로지스틱 회귀
로지스틱 회귀는 회귀의 장점을 살린 분류 알고리즘이다. 로지스틱 회귀가 선형회귀와 다른 점은 학습을 통해 선형 함수의 회귀 최적선을 찾는 것이 아니라 시그모이드(sigmoid) 함수 최적선을 찾고 이 시그모이드 함수의 반환값을 확률로 간주해 확률에 따라 분류를 결정하는 것이다. 로지스틱 회귀는 가볍고 빠르지만, 이진 분류 예측성능도 뛰어나다. 이 때문에 로지스틱 회귀를 이진 분류의 기본 모델로 사용하는 경우가 많다.
회귀계수를 보고 해석하는 방법은 아래와 같다.
- 회귀계수가 양수면 label에 양의 상관관계를 갖는다.
- 회귀계수가 음수면 label에 음의 상관관계를 갖는다.

| 목적 | import | API |
| Logistic Regression | from sklearn.linear_model import LogisticRegression | LogisticRegression() |
target인 인재등급(라벨링)은
S: 사내 핵심이라고 일컬어지는 현재시점 주요 직책자와 우수직원의 리스트
X: 우수한 고과를 가졌더라도 조기퇴사(7년 이내)한 인력의 리스트
C: 지속적으로 성과가 좋지 않은 저성과자
D: 중징계 이상인 자
A: 일반 직원리스트
S: 71, X: 36, C: 55, D: 28, A: 2,200
(파이썬) 로지스틱 회귀
모델 구축(사이킷런 라이브러리)
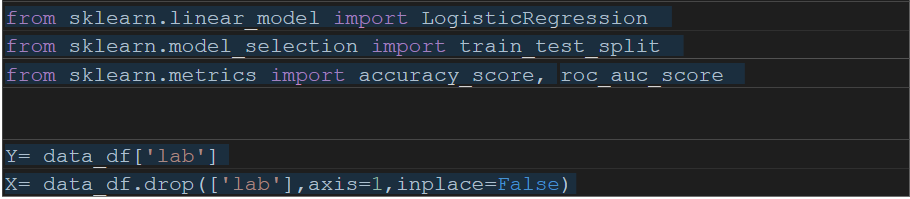
모델 학습/예측

모델 평가

하이퍼파라미터

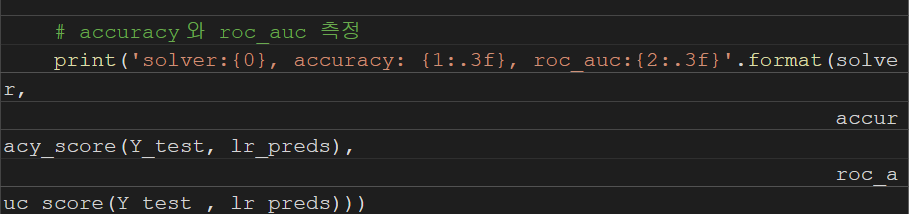
* solver : ‘newton-cg’, ‘lbfgs’, ‘liblinear’, ‘sag’, ‘saga’ 중 선택 가능, 회귀식을 최적화하는 알고리즘의 종류이며, 기본 값은 'lbfgs'. ‘newton-cg’, ‘lbfgs’, ‘liblinear’는 일반적으로 중소규모 데이터 세트에 권장되며, ‘sag’, ‘saga’ 는 대규모 데이터 세트에 더 적합
[기타]
penalty : 'l1', 'l2', 'elasticnet', 'none' 중에서 설정 가능, 'l2'가 기본 값이며, 복잡한 모델에 대한 규제를 1차 / 2차 / 혼합 / 미규제 중 어떻게 할 것인지에 대한 여부 선택
C : 규제 변수에 대한 계수 결정, 1.0이 기본 값이며, 클수록 panelty 강화
핵심인재인 S급인재는 다른 유형의 직원과 다른 요인이 있을 것이다라는 가설 검증을 위해 각 유형별 비교분석
1) S급과 C(저성과)/D(중징계)급 간 비교
예측 성능
accuracy: 0.979, roc_auc:0.979
solver:lbfgs, accuracy: 0.979, roc_auc:0.979
solver:liblinear, accuracy: 0.979, roc_auc:0.979
solver:newton-cg, accuracy: 0.979, roc_auc:0.979
solver:sag, accuracy: 0.511, roc_auc:0.500
solver:saga, accuracy: 0.511, roc_auc:0.500
정확도란, 분류한 데이터의 총수 중, 알맞게 분류된 데이터의 비율; AUC(곡선하면적)는, ROC (Receiver Operating Characteristic) 곡선의 아래쪽의 면적으로 이 값이 크면 클수록 분류성능이 좋다는 것을 표현하는 지표
회귀계수 값
| 매우유용 | 0.35~ |
| 유용 | 0.2~0.35 |
| 상황에따라상이 | 0.11~0.2 |
| 유용하지않음 | ~0.11 |
Saad, S., Carter, G. W., Rothenberg, M., & Israelson, E. (1999). Testing and Assessment: An Employer's Guide to Good Practices
선형 회귀분석과 로지스틱 회귀분석 모두 fit함수를 사용하여 학습한 후 coef_와 intercept_ 매개변수를 얻는다. 이 매개변수를 사용하여 선형 회귀분석에서는 회귀선으로 'coef_*X+intercept_'를 사용하며, 로지스틱 회귀분석에서는 sigmoid('coef *X+intercept')를 사용한다.
| 구분 | linear | logistic |
| asl | 0.36 | 1.79 |
| asm | 1.02 | 1.42 |
| rew | 0.09 | 0.67 |
| for | 0.21 | 0.53 |
| sex | 0.45 | 0.5 |
| deg | -0.29 | 0.43 |
| imp | 0.02 | 0.36 |
| prd | 0.05 | 0.19 |
| sta | 0.08 | 0.18 |
| upl | -0.1 | 0.09 |
| glb | 0 | 0.08 |
| upm | 0.05 | 0.05 |
| tor | 0.08 | 0 |
| ovs | 0 | 0 |
| cno | 0 | 0 |
| hom | -0.43 | -0.03 |
| dom | -0.05 | -0.11 |
| age | 0 | -0.13 |
| rep | -0.73 | -0.15 |
| rel | 0.01 | -0.21 |
| atn | -0.78 | -0.78 |
| pun | -0.85 | -1.18 |
인사고과와 징계 여부 차이는 당연한 것이고 성별과 어학(다수언어) 여부, 최종학력, 자기개발 기록이 중요요인 도출되었고, 휴직을 오래한 사람일수록 핵심인재와 거리가 멀었다.
2) S급과 A급(일반직원) 간 비교
예측 성능
accuracy: 0.962, roc_auc:0.621
solver:lbfgs, accuracy: 0.962, roc_auc:0.604
solver:liblinear, accuracy: 0.963, roc_auc:0.622
solver:newton-cg, accuracy: 0.963, roc_auc:0.622
solver:sag, accuracy: 0.959, roc_auc:0.500
solver:saga, accuracy: 0.959, roc_auc:0.500
회귀계수 값
| 구분 | linear | logistic |
| asl | 0.22 | 1.44 |
| rew | 0.24 | 1.24 |
| asm | -0.17 | 1.01 |
| deg | 0.04 | 0.58 |
| for | 0.01 | 0.5 |
| imp | 0.01 | 0.44 |
| glb | 0.51 | 0.29 |
| prd | -0.01 | 0.18 |
| upl | 0.11 | 0.15 |
| sta | 0.01 | 0.13 |
| upm | -0.08 | 0.04 |
| cno | 0 | 0 |
| sex | 0 | 0 |
| dom | -0.04 | 0 |
| ovs | -0.08 | -0.03 |
| tor | 0.01 | -0.04 |
| hom | 0 | -0.06 |
| age | -0.01 | -0.17 |
| rep | -0.02 | -0.19 |
| rel | -0.02 | -0.27 |
| pun | -0.14 | -0.27 |
| atn | -0.13 | -1.11 |
핵심인재가 일반직원보다 두드러진 차이는 최종학력과 어학이 우수하고 글로벌엑스퍼트(사내에서 주재원을 희망하는 직원들을 선발 및 장기간 교육하여 수료시키고 주재원 후보자로 올림) 경험자와 포상, 자기개발기록이 우수한 자임을 알 수 있고, 휴직과 징계와 거리가 멀었다.
3) S급과 X급(우수인재였지만 조기퇴사한 인력) 간 비교
예측 성능
accuracy: 0.939, roc_auc:0.923
solver:lbfgs, accuracy: 0.970, roc_auc:0.962
solver:liblinear, accuracy: 0.970, roc_auc:0.962
solver:newton-cg, accuracy: 0.970, roc_auc:0.962
solver:sag, accuracy: 0.606, roc_auc:0.500
solver:saga, accuracy: 0.606, roc_auc:0.500
회귀계수 값
| 구분 | linear | logistic |
| prd | 0.06 | 0.8 |
| rew | -0.04 | 0.69 |
| imp | 0.13 | 0.44 |
| tor | -0.1 | 0.32 |
| glb | -0.26 | 0.16 |
| dom | -0.44 | 0.13 |
| hom | 0 | 0 |
| rep | 0 | 0 |
| rel | 0 | 0 |
| cno | 0 | 0 |
| age | -0.01 | -0.03 |
| upl | -0.17 | -0.09 |
| upm | 0.09 | -0.13 |
| deg | 0.23 | -0.16 |
| sta | 0.03 | -0.18 |
| ovs | -0.02 | -0.2 |
| pun | 0.64 | -0.23 |
| sex | -0.11 | -0.24 |
| asm | 0.51 | -0.28 |
| asl | -0.45 | -0.64 |
| for | -0.07 | -0.68 |
| atn | -2.89 | -2.92 |
동일한 고성과자라 하더라도 장기근속하면서 핵심인재가 된 직원은 포상과 자기개발기록이 우수하고, 관광학을 전공한 직원일 가능성이 높다.
결과해석
핵심인재 요인도출
[‘어학(다수언어)보유’, ‘글로벌마인드’, ‘관광전공’, ‘고학력’, ‘자기개발’, ‘적극성’]
아래의 주요 가설에 답을 해 본다면,
1. 핵심인재는 단기고과 우수자라기 보다는 장기근속 하면서 회사의 주요 부문에서 우수한 성과와 함께 리더십과 회사정책에 적극적 참여하는 적극성을 가진 직원일 것이다.
⇒ 핵심인재는 평균이상의 우수한 고과와 함께 장기근속하고 회사정책에 적극적 참여하는 직원이 맞다. 다만, 상향평가 결과를 통한 리더십 관련은 낮은 상관도가 있었다.
2. 사내 핵심이라고 일컬어지는 현재시점 주요 직책자와 우수직원의 리스트를 S등급으로 구분하고, 우수한 고과를 가졌더라도 징계가 있거나 조기퇴사한 인력의 리스트는 X등급, 지속적으로 성과가 좋지 않은 저성과자 C등급, 일반 직원리스트는 A등급으로 구분하여 이들 사이에는 구별되는 특성요인이 있을 것이다.
⇒ 회사의 특성 상, 데이터를 통해 알아본 핵심인재의 특성은 해외근무에 관심이 많아 언어적인 면에서 우수하고, 회사의 프로그램이나 자기개발에 적극 참여하는 성향을 갖고 있다. 학력이 높아질수록 핵심인재로 남을 가능성이 크나 출신대학은 크게 좌우하지 않고 관광학 관련 전공자일수록 장기근속 가능성이 크다. 경중에 상관없이 징계기록 보유화 휴직이 장기간 이어지는 자는 핵심인재가 아닐 가능성이 크다.
3. 핵심인재는 반드시 고평가자는 아닐 것이다.
⇒ 핵심인재는 반드시 고평가자가 아니나 우수한 평가와 함께 회사의 조직문화와 어우러져 적극적으로 프로그램에 참여하고, 자기개발에 관심이 많은 성향의 직원일 가능성이 크다.
활용방안
채용 : 도출된 요인들에 대한 채용단계 별 가중치 상향
승진 : 추천모델 관련 별책부록
한계점
1. 역량모델링과 동일하게 핵심인재에 대한 가설도 사람의 가치판단이 들어갈 수 밖에 없다.(데이터 편향성)
2. HR데이터의 수집 한계가 명확하여 더욱 민감성과 직감을 요하는 의사결정 등은 기존 인사고과 기준적용 벗어나기 힘들 것이다.(데이터 수용성)
3. 포지션 별 요건정의 및 관점파악이 어렵다.
4. 개인의 특성요인이 아닌 관계분석(사내메신져/메일 분석 파일전송 등 인적 네트워킹 분석)을 통한 의도적으로 인식하지 못한 데이터 활용이 더 중요하다.
'People Insight' 카테고리의 다른 글
| 제약업계 다양성 지표 활용 사례 (0) | 2023.05.05 |
|---|---|
| 성장혼합모형(GMM)을 적용한 채용 PA (0) | 2023.04.22 |
| AI 기반 HR 텍스트 분석 : 자기소개서 스크리닝 (0) | 2023.04.14 |
| 직무기술서 유사도분석을 통한 내부 인재 추천 (0) | 2023.04.10 |
| 코린이도 한다, 텍스트 크롤링 (feat. ChatGPT, 구글링) (0) | 2023.04.09 |