
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- survival analytics
- ChatGPT
- 태그도 많이 치는거 힘들다..
- HR 데이터 분석
- 하나만 쓰자..
- LDA Topic Modeling
- Jobplanet
- 회귀분석
- HR
- Text mining
- HR데이터
- 채용 대시보드
- 성장혼합모형
- Pa
- 자기소개서 스크리닝
- PA201
- HR 애널리틱스
- Talent Analytics
- 데이터분석
- people analytics
- 유사도분석
- 피플 애널리틱스
- HR Analytics
- HR Anlaytics
- 다항로지스틱회귀분석
- PA 미래
- Workforce Analytics
- HRA
- HR대시보드
- 인사데이터
- Today
- Total
People-Analytics201
성장혼합모형(GMM)을 적용한 채용 PA 본문
본 포스팅은 PA201 구성원 ‘김나경’님에 의해 작성된 글입니다.
잘된 채용이란 무엇일까?
어떤 사람이 조직에 들어와서 눈에 보이는 성과를 내기까지는 시간이 꽤 오래 걸린다. 우리가 채용 이후 ‘A씨는 참 잘 뽑은 것 같아’라고 얘기하는 순간들을 돌이켜보면, 조직에 빠르게 적응하는 사람을 일컬을 때가 많다. 때문에 채용의 효과성을 검증할 때 중요하게 고려해야 하는 부분 중 하나는 "적응"이라 할 수 있겠다.
적응이란 새로운 조직 환경에 맞추어 응하는 것으로, 이는 개인이 조직에 가지는 태도로 나타난다. 이와 관련하여 조직장면에서 많이 연구되는 태도변인이 있다. 바로 조직몰입이다. 조직몰입은 '구성원이 자신의 조직에 헌신하고 기꺼이 조직을 위해 일하려 하는 정도, 그리고 조직 구성원으로 남아있고자 할 개연성'이라고 정의된다(박영석 등, 2017). 조직몰입은 적응의 지표일뿐만 아니라, 이직의도의 강력한 선행변인으로 확인되어 온 만큼(Tett & Meyer, 1993) 채용 후 이탈율을 관리하는 인사팀 입장에서 관심을 가져야 할 지표이기도 하다.
이 글에서는 성장혼합모형(GMM;Growth Mixed Model) 분석을 적용하여, '입사 후 시간의 흐름에 따른 조직몰입의 변화로 구성원들을 유형화하는 방법'을 소개하고자 한다. 이에 더하여, 선행/결과변인을 모형에 투입하여 '어떤 특성을 가진 구성원들이 어떤 유형에 속할지', '어떤 유형의 구성원들이 어떤 결과를 가져올지' 확인하고 예측해 볼 수 있는 방법을 공유한다. 본 포스팅을 통해 회사가 채용 과정에서 혹은 채용 이후 사회화나 교육단계에서 개입할 수 있는 실용적인 아이디어를 제공하고자 한다.
* 성장혼합모형(GMM)은 혼합모형, 잠재성장모형, 이항/다항 로지스틱 회귀 분석, 변량분석에 대한 이해가 선행되어야 정확히 분석하고 해석할 수 있기 때문에, 본 포스팅으로 구체적인 통계적 지식과 분석방법을 소개하는데 한계가 있다. 따라서, 기본적인 모형의 개념과 Analysis Case 공유를 통해 ‘Longitudal data를 활용한 채용 PA’에 대한 아이디어와 인사이트를 제공하는데 초점을 맞춘다.
성장혼합모형이란
가장 먼저, 혼합모형이 무엇인지 이해할 필요가 있다. 혼합모형의 혼합(Mixture)이란 데이터 안에 서로 다른 이질적인 집단이 존재하고 섞여있음을 의미한다. 즉, 내가 가진 데이터의 집단이 homogeneous하지 않다는 것을 말한다. 이는 기존에 많이 활용되는 상관분석, 변량분석 등의 변인중심적 분석과 차별되는 점이다. 변인중심적 접근에서는 표본의 모든 구성원들이 동질적이며, 분석에서 확인된 변인 간 관계가 구성원 모두에게 적용된다고 가정한다. 하지만 혼합모형은 데이터 내에 이질적인 집단 구성원들이 섞여있으며, 이러한 집단은 변인, 구성개념, 추정계수 등의 조합으로 구분될 수 있다고 가정한다. 이를 사람중심적 접근방식이라 한다.
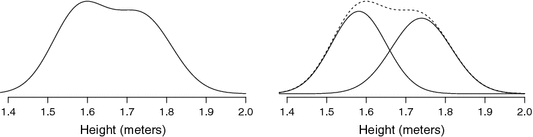
혼합모형에는 잠재계층모형, 잠재프로파일모형, 잠재전이모형, 혼합회귀분석, 성장혼합모형 등이 있으며, 데이터 안에 다양한 잠재집단을 확인하여 사람들을 집단화, 유형화할 수 있다는 장점이 있다. 또한, 모형을 확장하여 영향을 주는 배경변인(선행변인)과 결과변인을 추가할 수 있다. 이 글에서는 여러 가지 혼합모형 중에서도 종단데이터를 활용한 성장혼합모형을 살펴보려 한다.
성장혼합모형을 살펴보기 앞서, 잠재성장모형(LGM; Latent Growth model)을 먼저 살펴보자. 잠재성장모형이란 시간의 흐름에 따른 관심변인의 변화를 추정하는 분석방법이다. 예를 들어 우리 회사 구성원들의 이직의도가 시간의 흐름에 따라 어떻게 변화하는지 확인하기 위해, 연도별 데이터를 축적하고 잠재성장모형 분석을 시행할 수 있다. 이를 통해 전반적인 구성원의 이직의도 변화 기울기를 추정할 수 있으며, 이직의도가 높아지는 peak 시점을 확인하여 retention을 위한 적절한 보상(인센티브, 휴가 등)을 지급하는 시점을 결정하는 등의 실무적인 의사결정을 내릴 수 있다.
잠재성장모형을 분석하다 보면 추정된 기울기의 variances가 높다는 것을 확인하곤 하는데, 이는 조직원들의 변화정도를 단순히 하나의 기울기로 설명할 수 없다는 것을 의미한다. 즉, 내가 가진 데이터 안에는 다양한 변화 기울기를 가진 사람들이 존재한다고 추정해 볼 수 있다. 예를 들어 어떤 사람은 계속 증가하는 유형, 어떤 사람은 증가하다가 감소하는 유형, 어떤 사람은 계속 감소하는 유형에 속할 수 있다. 이러한 잠재적인 집단을 확인하고 사람들을 유형화하는 분석이 성장혼합모형이다.
성장혼합모형의 분석 과정은 다음과 같다. 먼저, 종단데이터 클리닝이 필요하다. 각 개인별로 시간의 흐름에 따라 관심변인이 정리되도록, 각 시점은 모든 사람에게 동일하도록 데이터 구조를 정리해야 한다(결측값 정리 등의 기타 클리닝은 당연히!). 다음으로는 잠재집단 수를 확인하기 위해 집단 수를 하나씩 늘려가며 성장혼합모형을 분석한다. 이때 모형의 적합도를 확인할 수 있는 여러 가지 지표들을 확인해야 하는데, 모델 fit 지표인 AIC(Akaike Information Criterion), BIC(Baysian Information Criterion), Entropy, LMRT(Lo-Mendell-Rubin adjusted lrt Test), BLRT(Bootstrapped Likelihood Ratio Test), 수렴확인(Global maxima)등을 확인한다. 해당 지표들을 모형별로 비교하여, 연구자는 가장 적절하다고 판단되는 잠재집단 수를 결정하게 된다. 잠재집단 수가 결정되었다면, 각 집단이 시간의 흐름에 따라 어떻게 변화하는지 확인하여 그 특징을 잘 드러내는 이름을 붙여주면 된다. 마지막으로, 확인된 잠재계층 모형에 선행변인과 종속변인을 추가하여 모형을 확장한다.
이제 실제 분석 케이스를 통해 성장혼합모형을 적용한 채용 PA를 살펴볼 것이다.
'입사 후 시간의 흐름에 따라 조직몰입 변화유형이 서로 다른 집단이 있는지'
'어떤 특징/배경을 가진 사람들이 어떤 유형에 속할 확률이 높은지',
'어떤 유형의 사람들이 어떤 결과를 가져오는지'
에 집중하며 Analysis Case를 읽어보도록 하자.
Analysis Case
소개할 케이스는 한국노동패널데이터 17-19차(2014-2016년; 3개년) 종단 데이터를 활용한 결과이다. 데이터는 T1 시점인 17차(2014년) 설문에서 ‘당해연도에 회사에 입사했다’고 응답한 사람들만 추출하여 분석하였으며, 이렇게 걸러낸 사람들은 모두 535명이었다.
분석에서 잠재집단을 추정하기 위해 활용한 관심변인은 '조직몰입'으로, 총 5문항으로 측정되었으며 문항 내용은 아래와 같았다. 분석에는 5문항의 평균값을 사용하였다.
현재 _____님께서 근무하고 계시는 직장(일자리)에 대한 _____님의 평소 생각은 어떠하십니까?
다음의 각 항목에 대해서 얼마나 동의하시는지 혹은 동의하지 않으시는지 그 정도를 표시해 주십시오.
5점 척도 : (1) 전혀 그렇지 않다 - (5) 아주 그렇다
1) 지금 근무하고 있는 직장(일자리)은 다닐만한 좋은 직장이다
2) 나는 이 직장(일자리)에 들어온 것을 기쁘게 생각한다
3) 직장(일자리)을 찾고 있는 친구가 있으면 나는 이 직장을 추천하고 싶다
4) 나는 내가 다니고 있는 직장(일자리)을 다른 사람들에게 자랑할 수 있다
5) 별다른 일이 없는 한 이 직장(일자리)을 계속 다니고 싶다
조직몰입의 변화 기울기로 추정되는 잠재집단 수를 2개에서 4개로 늘려가며 혼합성장모형 분석을 시행했다(분석 조건 : 1차 함수/무조건모형/잠재집단 내 variances 0으로 고정). 분석에는 Mplus를 사용했으며 모형 fit 지표들을 확인한 결과, 3개의 잠재집단 모형의 fit이 가장 우수하다고 판단되었다.
잠재집단 3개 모형 fit
AIC = 2134.70, BIC = 2182.077 (작을수록 좋은)
Entropy = 0.80 (클수록 좋은)
LMRT p-value = 0.02, BLRT p-value = 0.00 (p-value 유의한 지 확인)
분석 결과로 확인된 3가지 집단(Class) 특성을 살펴본 결과는 아래와 같았다.
| 초기값 (T1) | 기울기 | |
| Class 1 | 2.670** | -0.191** |
| Class 2 | 3.107** | -0.004 |
| Class 3 | 3.650** | 0.060* |
* p < 0.05, ** p < 0.001

추정된 기울기와 그래프 모양을 해석하여, 각각의 잠재집단에 이름을 붙였으며 각각의 Proportions와 Count는 아래와 같았다.
C1(조직몰입의 초기값이 높고, 갈수록 증가하는 유형 = 증가형) 32.1% (172명)
C2(조직몰입의 초기값이 보통 수준이고, 변화가 없는 유형 = 변화 없음형) 58.2% (312명)
C3(조직몰입의 초기값이 낮으며, 갈수록 감소하는 유형 = 감소형) 9.6% (51명)
위와 같은 결과를 통해, 분석한 데이터 모집단(대한민국의 근로자)의 입사 후 조직몰입 변화 유형은
3가지(증가형 / 변화 없음형 / 감소형)임을 알 수 있다.
다음으로, 모형을 확장하여 3가지 잠재집단으로 확인된 모형에 선행변인을 투입해 보았다. 총 9가지 변인들을 투입하였으며, 인구통계학적 변인 외 측정변인들은 인과관계 확인을 위해 T1 시점에 측정된 변인들을 사용하였다.
[선행변인 9가지]
1. 성별 : 남/여
2. (만) 나이
3. 정규직유무 : 정규직/비정규직
4. 생애 첫 일자리 유무 : 신입/경력
5. 근속개월 : 17차 응답 당시 월 - 입사 월
6. 업무량(T1) : 평소 하루 업무량은 (정규근로시간/전체근로시간)에 비해 어느 정도 수준입니까?라는 2문항 평균; 5점 척도 (1) 매우 적다 - (5) 매우 많다
7. 근무시간 자율성(T1) : 출퇴근 시간 변경 가능 여부, 근무시간 개인용무 가능 여부라는 2문항 합점수; 2점 척도 (0) 불가능 - (1) 가능
8. 일의 수준(T1) : 현재 주로 하는 일자리에서 하고 계시는 일이 본인의 교육 수준/기능 수준과 비교하여 어느 정도 맞다고 생각하십니까?라는 2문항 평균 - 5점 척도점척도 (1)(1) 수준이 매우 낮다 ~ (5) 수준이 매우 높다
9. 일 생활 갈등(T1) : 6개 문항의 평균 - 5점 척도 (1) 매우 그렇지 않다 - (5) 매우 그렇다
1) 일 때문에 항상 너무 피곤해서 일 이외에 다른 활동을 하기 어렵다 / 2) 일 때문에 잠을 잘 못 자는 불면증이 자주 있다 / 3) 업무에 대한 생각 때문에 다른 활동을 해도 재미가 없다 / 4) 일 때문에 개인적인 생활이 종종 방해를 받는 것 같다 / 5) 직장 일 때문에 개인적으로 해야 할 일을 미루는 경우가 자주 있다 / 6) 직장 일 때문에 중요한 개인적인 일 을 할 수 없는 경우가 자주 있다
선행변인을 모형에 투입하여 분석한 결과, ( 잠재집단모형에 선행변인을 투입하는 분석 = 이항/다항 로직스틱 )
정규직일수록C2(변화 없음형)와 C3(감소형)보다는 C1(증가형)에 속할 확률이 높았다.
일의 수준이 높을수록 C3(감소형)보다는 C1(증가형)에 속할 확률이 높았다.
일 생활 갈등이 높을수록 C1(증가형)보다는 C2(변화 없음형)에 속할 확률이 높았다.
* 모두 p < 0.01 수준으로 유의
반면 성별, (만) 나이, 생애 첫 일자리 유무, 근속개월, 업무량, 근무시간 자율성 변인들은 유의한 결과가 나오지 않았다.
이러한 결과를 통해,
비정규직보다는 정규직이, 입사 첫해 본인 일의 수준이 높다고 생각하는 사람일수록/일 생활 갈등이 낮을수록
증가형 잠재집단(조직몰입이 초기에 높고, 갈수록 증가하는 사람)에 속할 확률이 높다는 것을 알 수 있다.
이를 조직장면에서 분석한 결과였다고 가정한다면,
조직몰입 증가형 잠재집단이 될 확률이 높은 조건을 가진 사람을 채용한다거나(채용 요인),
입사 후 적당히 높은 수준의 직무난이도를 세팅해 주고, 일 생활 갈등을 줄여줌(예: 스트레스 관리 교육 등)으로써(사회화 개입)
증가형 잠재집단의 Proportion을 높일수 있는 방안을 세울 수 있다.
마지막으로, 확인된 잠재집단이 어떤 태도나 행동을 보이게 될지 확인하고 예측해 보기 위해 결과변인을 추가하여 모형을 확장해 보았다. 총 5가지 결과변인을 활용했으며, 인과관계를 고려하여 모두 T3(19차) 시점에 측정한 변인을 사용하였다.
[결과변인 5가지]
1. 직무만족(T3) : 5문항 평균 - 5점 척도 (1) 전혀 그렇지 않다 - (5) 아주 그렇다
1) 나는 현재 하고(맡고) 있는 일에 만족하고 있다 / 2) 나는 현재 하고(맡고) 있는 일을 열정적으로 하고 있다 / 3) 나는 현재 하고(맡고)있는 일을즐겁게 하고 있다 / 4) 나는 현재 하고(맡고)있는 일을보람을 느끼면서 하고 있다 / 5) 별다른 일이 없는 한 현재 하고(맡고)있는 일을 계속하고 싶다
2. 일자리만족(T3) : _님의 주된 일자리에 대해 전반적으로 얼마나 만족하십니까? 5점 척도 1) 매우 불만족 ~ (5) 매우 만족
3. 일만족(T3) : _님의 주된 일에 대해 전반적으로 얼마나 만족하십니까? 5점 척도 1) 매우 불만족 ~ (5) 매우 만족
4. 이직의도(T3) : 혹시 다른 직장으로의 이직을 생각하십니까? - (1) 적극적으로 이직할 의향이 있다 (2) 이직을 고려 중이다 (3) 아니요 / (1)과 (2)를 한데 묶어 (1) 이직의도 유, (3)은 (0) 이직의도 무로 코딩)
5. 중간퇴직유무 : T2(18차) 혹은 T3(19차) 응답 시 일을 그만두었다고 하거나, 다른 일을 시작했다고 한 경우 퇴직(1)으로, 나머지는 계속 근로(0)로 코딩
결과변인 분석 결과, ( 잠재집단모형에 결과변인을 투입하는 분석 = 교차분석, 변량분석 )
연속변인인 직무만족, 일자리만족, 일만족의 경우 추정된 평균들이 C1(증가형) - C2(변화 없음형) - C3(감소형) 순으로 낮아졌고, 각 class 간 평균 차이가 유의한 것으로 확인되었다.
범주변인인 이직의도, 중간퇴직유무는 이직의도의 경우 C1(증가형)의 경우 이직을 원한다는 비율이 87%, C2(변화 없음형)의 경우 88%, C3(감소형)의 경우 100%로 C1과 C3, C2와 C3에서만 유의한 차이가 확인되었다.
중간퇴직유무의 경우 C1(증가형)의 경우 중간 퇴직한 비율이 41%, C2(변화 없음형)의 경우 25%, C3(감소형)의 경우 69%로 C1과 C3에서만 유의한 차이를 확인되었다.
* 모두 p < 0.01 수준으로 유의
이러한 결과를 통해,
조직몰입 감소형 집단일수록 본인의 직무/일자리/일에 대한 만족도가 낮음을 알 수 있으며
특히 감소형 집단은 3년 후 이직을 원한다는 비율이 다른 집단에 비해 높음을 알 수 있다.
주목할만한 점은 실 퇴직유무 결과인데, 의외로 퇴직률이 가장 낮았던 집단은 '변화 없음형'이었으며
'증가형' 집단의 퇴직률이 '변화 없음형'보다 높았다는 점에서 추가적인 고찰이 필요해 보인다.
이를 조직장면에서 분석한 결과였다고 가정한다면,
퇴직률을 낮추기 위해 감소형 잠재집단으로 확인되는 사람들을 집중관리 한다거나,
입사 후 적응도가 높은 잠재적인 핵심인재 집단인 증가형 집단의 퇴직 사유를 보다 면밀히 분석하여
이들이 퇴직하지 않도록 전략을 세울 수 있겠다.
* (참고) 혼합모형에 선행변인(독립변인)과 종속변인을 추가하는 방법에는 크게 2가지가 있다. 첫 번째, 3단계 추정방법으로 ①독립, 종속변인이 없는 기본 혼합모형 추정, ②각 개인이 속할 확률이 높은 잠재계층 추정, ③분류오류를 고려하여 독립,종속변인 효과 추정의 단계를 거쳐 분석한다. 두번째, Mplus 분석 패키지에서 제공하는 추정로직이 셋팅된 code를 활용(독립변인 code : R3STEP, 종속변인 code : DU3STEP, DE3STEP, BCH, DCON-연속형/DCAT-범주형) ** 두번째 방법이 본 포스팅 분석에 Mplus를 활용한 이유이기도 하다.
마무리하며
본 아티클에서 공유한 케이스의 한계점은 다음과 같다.
첫번째, 분석에 사용한 문항의 신뢰도/타당도가 떨어진다는 점이다. 실무적 측면에서는 크게 문제 삼지 않을 수 있지만, 연구장면에서는 측정의 신뢰도와 타당도를 매우 중요하게 여기기에, 연구장면에서 타당화된 문항을 쓰지 않았을 때 결과의 신뢰성이 비난받을 수 있다. 그럼에도 불구하고, 분석에 사용된 대부분의 문항들의 안면타당도가 높고, 평균화된 개별 문항들의 내적신뢰도가 양호한 수준이었기에 큰 문제로 보이지는 않는다.
두 번째, 본 분석에서 적용한 추정방법의 한계이다. 성장혼합모형을 분석하는 방법은 아래 3가지가 있으며 본 분석에서는 1번 추정방법을 적용했다.
1) intercept와 slope의 variance를 0으로 고정하는 방법(Latent Class Growth Model)
2) 각 class의 intercept와 slope의 variance를 같다고 하여 추정하는 방법(GMM)
3) 각 class의 intercept와 slope의 variance를 각기 다르게 모두 추정하는 방법(GMM)
1번 방법의 경우, 시뮬레이션 연구 결과에 따르면 분산을 제약하기 때문에 설명되지 못한 분산이 추가 잠재집단으로 나올 수 있다는 비판을 받는다. 때문에 2번 혹은 3번 방법을 적용하는 게 안전한 방법이지만, 어떤 이유에서인지 1번 추정을 적용했을 때만 수치들이 유의하게 확인되었다. 2번 방법으로 추정했을 때, Class proportions와 각 Class의 intercept와 slope의 mean가 거의 같음에도 불구하고 수치적으로 모형이 유의하지 않은 부분에 대해서는 수학적으로 어떤 의미를 가지는지 좀 더 고민하고 분석결과를 받아들일 필요가 있겠다.
세 번째, 결측값의 문제이다. 데이터를 세팅할 때 만일 18차 혹은 19차에 퇴직했거나 이직했다면, 그 사람들의 그 해의 조직몰입은 결측 처리하였는데 이에 따라 결측값은 2가지 의미를 가지게 된다.
1) 존속자이지만 그 해 응답하지 않아서 결측
2) 중간에 퇴직하여 결측
결측값을 FIML(완전정보 최대우도) 방법을 적용하여 처리하였지만, 서로 다른 의미를 가지는 결측값을 모두 동일하게 처리하는 게 안전한 방법인지 고민해 볼 여지는 남아있다.
이상, 여기서 언급하지 않은 한계점이 많지만 분석의 완성도보다는 인사이트 공유에 초점을 맞춰주면 좋겠다 :)
끝으로,
본 아티클에서는 "입사 후 적응"의 측면에서 종단데이터를 활용한 채용 PA를 소개하였다.
혼합모형은 잠재적인 집단을 도출할 수 있다는 점에서, 집단 별 관리방안에 대한 인사이트를 주기 때문에
실무적으로 매력적인 분석 방법이다.
더욱이, 본 아티클에서 소개한 혼합성장모형(GMM) Analysis Case는
많은 조직에서 주기적으로 수집하고 있는 Longitudal Data(예: 조직진단)를 활용할 수 있는 하나의 예로서,
이 글을 읽고있는 PA담당자들에게 보다 폭 넓은 분석 아이디어로 이어질 수 있는 좋은 인사이트가 되기를 희망한다.
참고문헌
박영석, 서용원, 이선희, 이주일, & 장재윤. (2017). 조직심리학. 서울:㈜ 시그마프레스.
Oberski, D. (2016). Mixture Models: Latent Profile and Latent Class Analysis. In: Robertson, J., Kaptein, M. (eds) Modern Statistical Methods for HCI. Human–Computer Interaction Series. Springer, Cham.
Tett, R. P., & Meyer, J. P. (1993). Job satisfaction, organizational commitment, turnover intention, and turnover: Path analyses based on meta-analytic findings. Personnel Psychology, 46: 259-293.
'People Insight' 카테고리의 다른 글
| 채용 적합도 파악을 위한 다중 회귀 분석 (0) | 2023.05.07 |
|---|---|
| 제약업계 다양성 지표 활용 사례 (0) | 2023.05.05 |
| 핵심인재 요인도출 (0) | 2023.04.22 |
| AI 기반 HR 텍스트 분석 : 자기소개서 스크리닝 (0) | 2023.04.14 |
| 직무기술서 유사도분석을 통한 내부 인재 추천 (0) | 2023.04.10 |



