
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 인사데이터
- Pa
- Workforce Analytics
- 피플 애널리틱스
- 회귀분석
- Talent Analytics
- HR Analytics
- 태그도 많이 치는거 힘들다..
- 다항로지스틱회귀분석
- people analytics
- HRA
- 유사도분석
- HR
- survival analytics
- Jobplanet
- Text mining
- HR 데이터 분석
- 성장혼합모형
- 자기소개서 스크리닝
- HR 애널리틱스
- 채용 대시보드
- HR데이터
- PA201
- 데이터분석
- PA 미래
- 하나만 쓰자..
- LDA Topic Modeling
- HR대시보드
- ChatGPT
- HR Anlaytics
- Today
- Total
People-Analytics201
최근 N년간 부서별 입사자/재직자/퇴직자 수 계산하기 본문
아래 글은 PA201 스터디 구성원 BCD 님에 의해 작성된 글입니다.
데이터 분석은 어렵다. 상관관계, 회귀분석, 의사결정트리 등 이름만 들어도 어려운 분석이 도처에 깔려있다. 이렇게 무슨말인지 모르는 분석 이 아니더라도... 기본적인 통계, 인원 수 집계 또한 필자에겐 어렵다... 그래서 필자는 근성으로 데이터 분석을 한다. 근성으로 시작해서 근성으로 끝난다. 안되면 될 때까지... 그게 내 데이터분석 신조이다.
이 이야기를 왜 꺼내느냐? 이렇게 어렵고 근성이 필요한 분석들이 남들에게는 매우 쉬워보일 수 있기 때문이다. 특히 엑셀 팡션을 잘 다뤄보지 않은 사람들은 회사 내 재직자 수 및 입사자 수를 대충 타닥! 하면 나오는 건 줄 안다.
팀장 "BCD 대리~ 오늘 오전까지 최근 n년간 부서별 입사자/재직자/퇴직자 수 변화를 월별로 보고해줘요."
BCD 대리 "오전까지요..? 그건 제 근성으로 안ㄷ..."
팀장 "대충 피벗 돌리면 나오잖아~"
울화가 치밀지만, 내 팀장을 탓할 수 없다. 왜냐면 내 상사가 아니라 다른 누군가도 대충 피벗 돌리면 나오는 걸로 알테니까... 그래서 이번에도 나는 근성을 발휘한다.
인원 수(Head Count)를 계산하기 위해서는 어떤 데이터가 필요할까?
인사팀 실무자가 데이터를 뽑을 때는 인사시스템(ERP 등)에서 "조회 기준일"을 설정하고, 해당 일자 기준으로 명단을 뽑는다. 이 때 시스템의 종류에 따라 재직자/퇴직자를 따로 조회해야하는 경우가 있기도 하다.
왜 조회 기준일이 필요한가? 이는 직원의 직급 및 부서 등이 기준일자(최종 발령)에 따라 달라지기 때문이다.

따라서 특정일자(예들들어 23년 1월 31일) 기준으로 조회를 한다면, 해당일자의 직급과 부서만 나오기 때문에 과거의 부서가 나오지 않아 최근 10년간의 부서별 직원 수를 확인 할 수 없다!
그러면 어떻게 해결하나? 방법은 두 가지다(아니 사실 한가지다).
첫번째 방법은 발령데이터를 가져와서 인사명부와 매칭 시키는 것이다. 특정 기준일을 임의로 생성하고, 거기에 맞는 최신 발령을 땡겨오면 된다. (엑셀 등으로도 가능한 작업이지만, 데이터가 많아지면 어렵다)
두번째 방법은 실무자가 매달 말일(또는 초일) 기준으로 계속 조회하고 저장하고, 조회하고 저장하고, 조회하고 저장하고를 반복해서 마지막에 모든 파일을 합치는 것이다. 참 쉬워보인다. 하지만 실제로 하게 되면 엄청난 근성이 필요하다. 일단 조회하고 저장하는 것부터 생각보다 시간이 많이 소요되고, 합칠 때도 해당 파일별로 조회일 열(column)을 생성해줘야 한다.
처음에 방법은 한가지라고 한 이유는 이 때문이다. 정말 많은 데이터를 다룰 때는 두번째 방법이 의미가 없다. 실제로 모든 데이터는 "기준정보", "발령", "마스터 정보" 등으로 구성되기 때문에, 시스템적으로 볼 때 첫번째 방법을 사용하면 모든 조회일별 명부를 만들 수 있고 두번째방법이 필요없다.
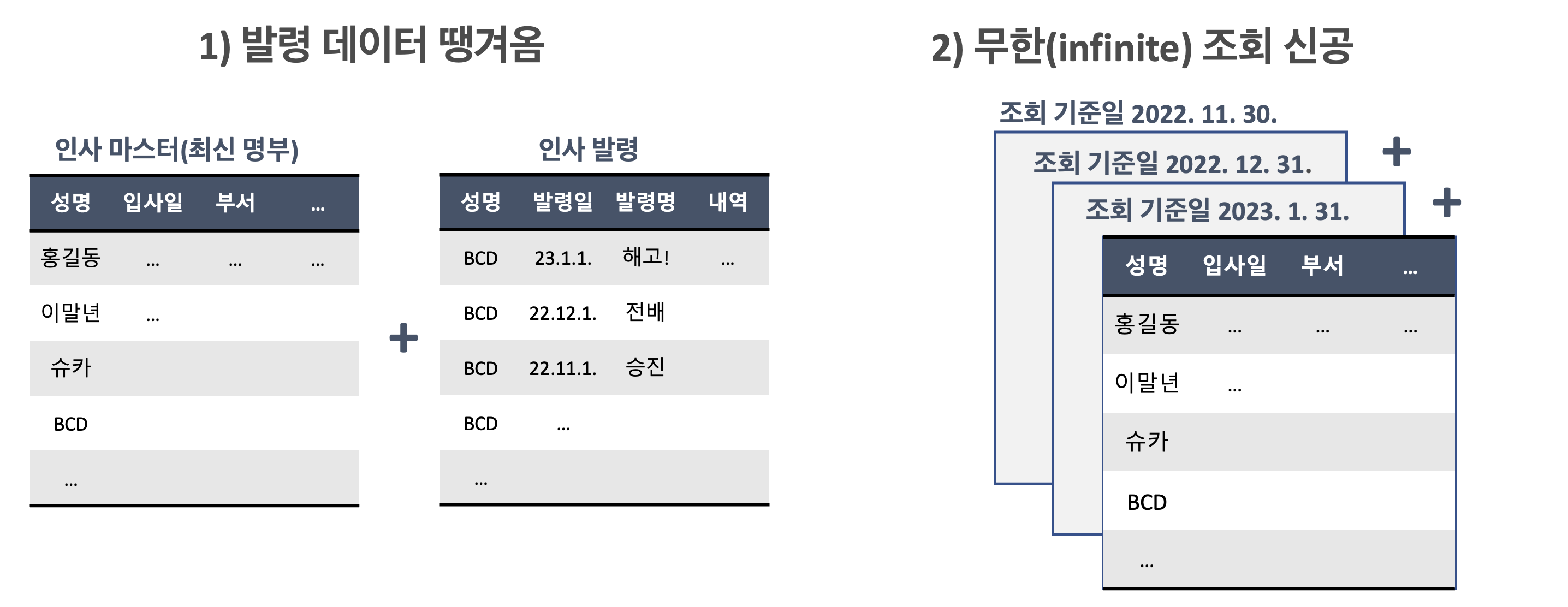
뭐 어쨌든 저쨋든 이러저러한 방법들을 사용하면, 결국 아래와 같은 패널 데이터(Panel Data)를 구성할 수 있다(아래는 예시다).
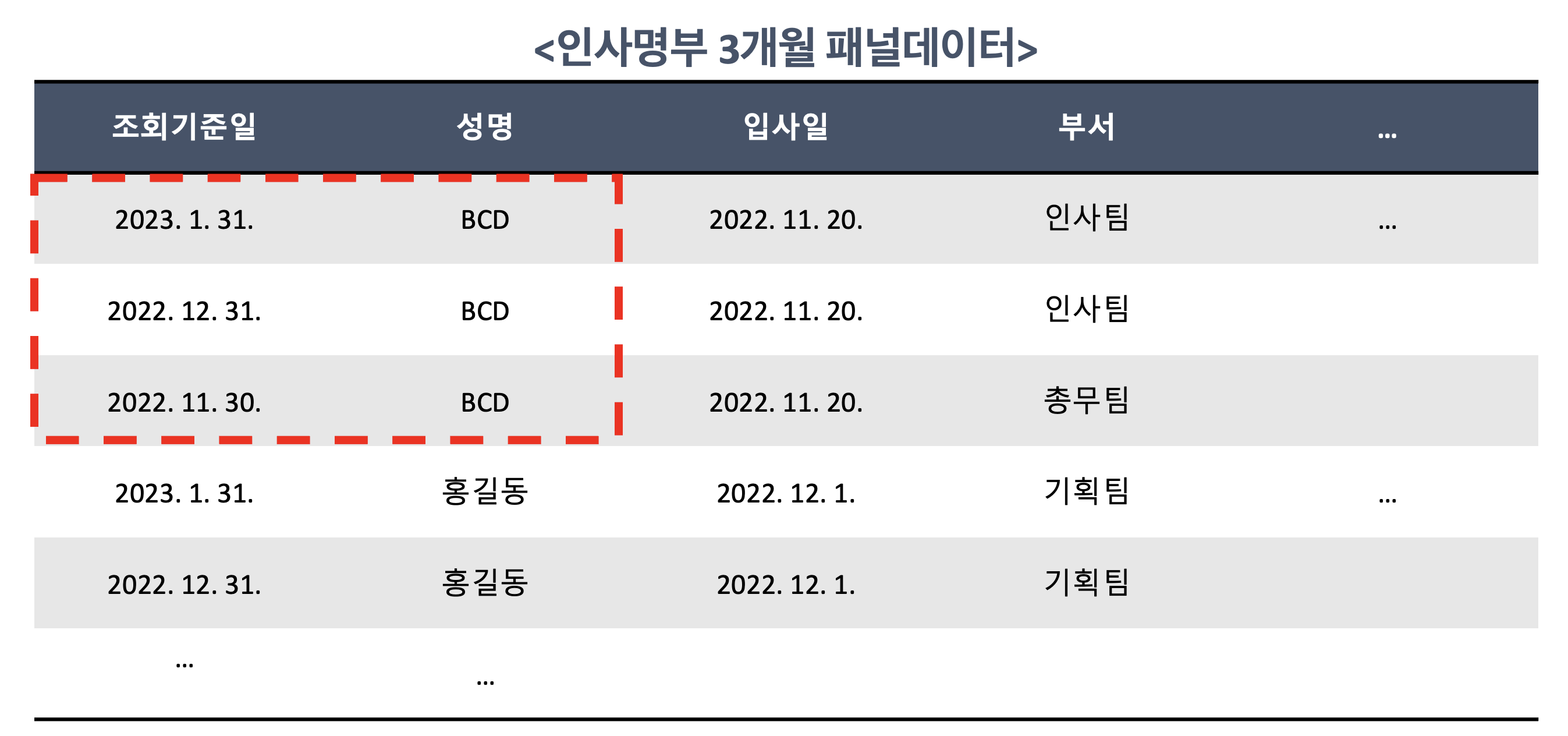
이때 주의할 점은 입사자 및 재직자의 수 뿐만아니라, 퇴직자 수의 인원을 구해야하기 때문에 위 n기간 인사명부에 퇴직자까지 들어가야 한다는 것이다. 다만 퇴직상태의 인원은 퇴직한 달까지만 들어가야 한다. 예를들어 23년 1월 20일에 퇴직했으면, 기준일이 23년 1월 31일인 명단, 22년 12월 31일 명단에는 들어가지만, 23년 2월 28일 명단에는 들어가면 안된다!
(실습) 인원 수를 한번 뽑아보자!
이렇게 데이터를 구성했다면, 이제 최근 N년간부서별입사자/재직자/퇴직자 수 변화 를 구할 준비는 다 됐다. 이제 대충 인터넷에 돌아다니는 데이터로 실습해보자... 라고 생각했는데, 인터넷에 대충 돌아다니는 데이터는 특정 시점의 횡단면 데이터만 존재할 뿐, 여러 기간을 가진 패널 형태의 HR 데이터가 아니었다.
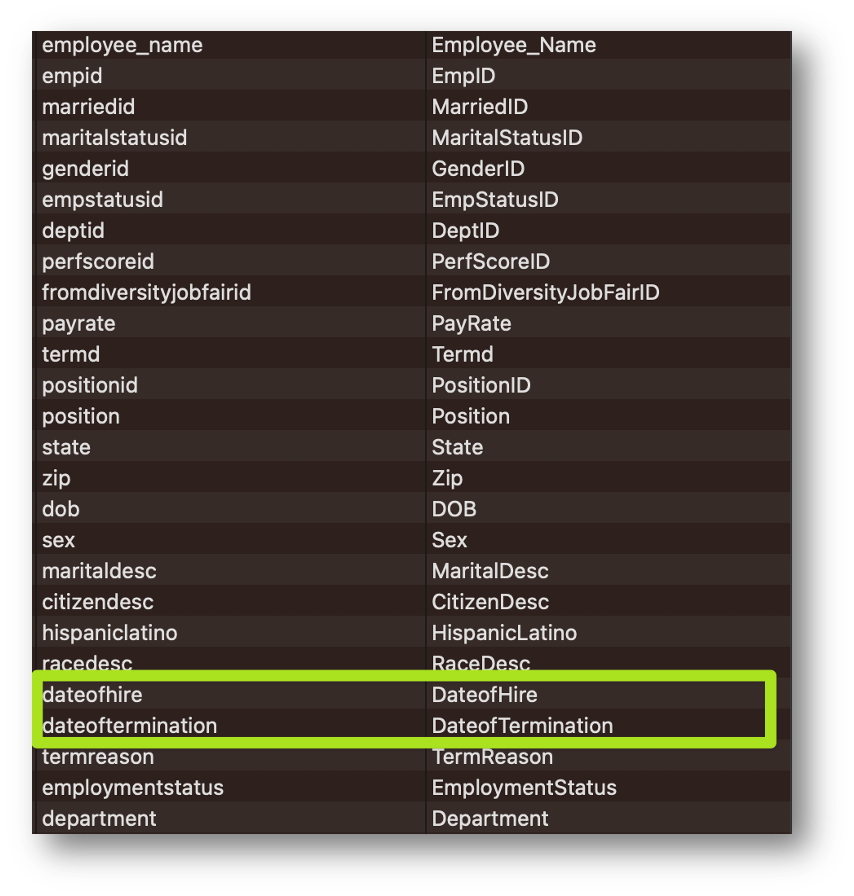
그래! 그러면 근성을 발휘해서 직접 데이터를 만들어보자.
이 데이터에는 개인별 입사일과 퇴사일이 기재돼있다.
필자는 Stata라는 사용해서 전처리를 진행하고, R을 사용해서 시각화를 해볼 예정이다.
Stata는 경제학 분야에 종사하는 여러 근성가이(또는 레이디)들이 사용하는 통계 Tool인데, 복잡하지 않고 직관적이어서 필자가 사랑하는 프로그램이다.
1. 데이터 불러오고, 랜덤으로 부서 매칭하기

복잡해 보이지만, 사실 별거 없다.
그냥 데이터 불러와서 필요한 변수 추출하고, 날짜 변수는 날짜 형식으로 지정해주고, 부서는 내가 제일 좋아하는 5개로 매칭시켜주었다.
여기서 부서 랜덤 매칭은 1~5 사이의 숫자가 같은 확률로 나오게 시뮬레이션 한 후, 각 숫자에 인사팀, 재무팀, 기획팀, 구매팀, 혁신팀으로 이름 붙여준 것이다.
2. 데이터를 월별로 저장하고, 패널데이터 셋 만들기

이후 각 데이터를 월별로 루프를 돌려서 저장해주면 되는데, 필자의 경우 루프문을 사용해 기준일을 생성하고, 기준일을 기준(?)으로 입사일이 더 크면 행 삭제, 퇴직일이 같거나 작으면 행 삭제를 진행했다. 이 때 필자는 기준일을 각 월의 말일로 사용했는데, 그 방식이 재미있다. 일단 모든 월을 초일(1일)로 날짜를 생성하고, 이후 1개월을 더하고 1일을 빼는 방식으로 말일을 만들었다. 이런 방식으로 아래와 같이 있는 여러개의 파일을 제작했다.

그리고 이렇게 만들 월별 인원을 아래로 주욱 합치는 방식(long form)으로 데이터를 붙이고, 마지막으로 퇴직한 사람들의 리스트를 합쳐주었다.
퇴직한 사람들은 해당 월의 명부에 존재하지 않는데, 왜냐하면 내가 이미 각 말일 기준으로 퇴직일이 같거나 작은 경우 모두 삭제 했기 때문이다. 우리는 기준일과 퇴직일이 같을 때, 해당 월에 퇴직한 사람으로 보고 카운트를 해야하기 때문에 이렇게 붙여주었다.
이후, 기준일과 입사일, 퇴사일 등이 같은지를 비교하여 "당월재직", "당월입사", "당월퇴직" 등을 구하고, 최종 데이터셋을 생성시킨다. 예를들어 당월재직의 경우에는 기준일보다 입사일이 빠르면서 퇴직일은 기준일보다 큰 경우에는 1, 아니면 0으로 코딩한다.

3. 월별/부서별 입사자, 재직자, 퇴직자 집계
여기까지 왔으면 이제 정말 끝났다. 이제는 정말 대충 피벗만 돌리면 집계량이 나온다. 우리는 기준일 또는 기준일/부서 등을 그룹으로 "당월재직", "당월입사", "당월퇴직"의 합계를 구하기만 하면 된다!

4. 시각화
시각화를 위해 해당 집계를 엑셀로 저장한 후, R로 불러와 보았다. 필자는 R을 정말 잘 못다루는데, R을 잘 다루는 여러 고수분들께서 필자같은 사람들을 위해 아주 편하게 시각화할 수 있는 패키지를 만들어 놓았다. 그것은 바로 ggplot, plotly, esquisse이다.
해당 패키지에 대해서는 다음에 조금 더 설명하는 것으로 하고... 우선은 위 데이터 셋을 사용해 간단히 시각화 해보았다. 그 결과는 아래와 같다.
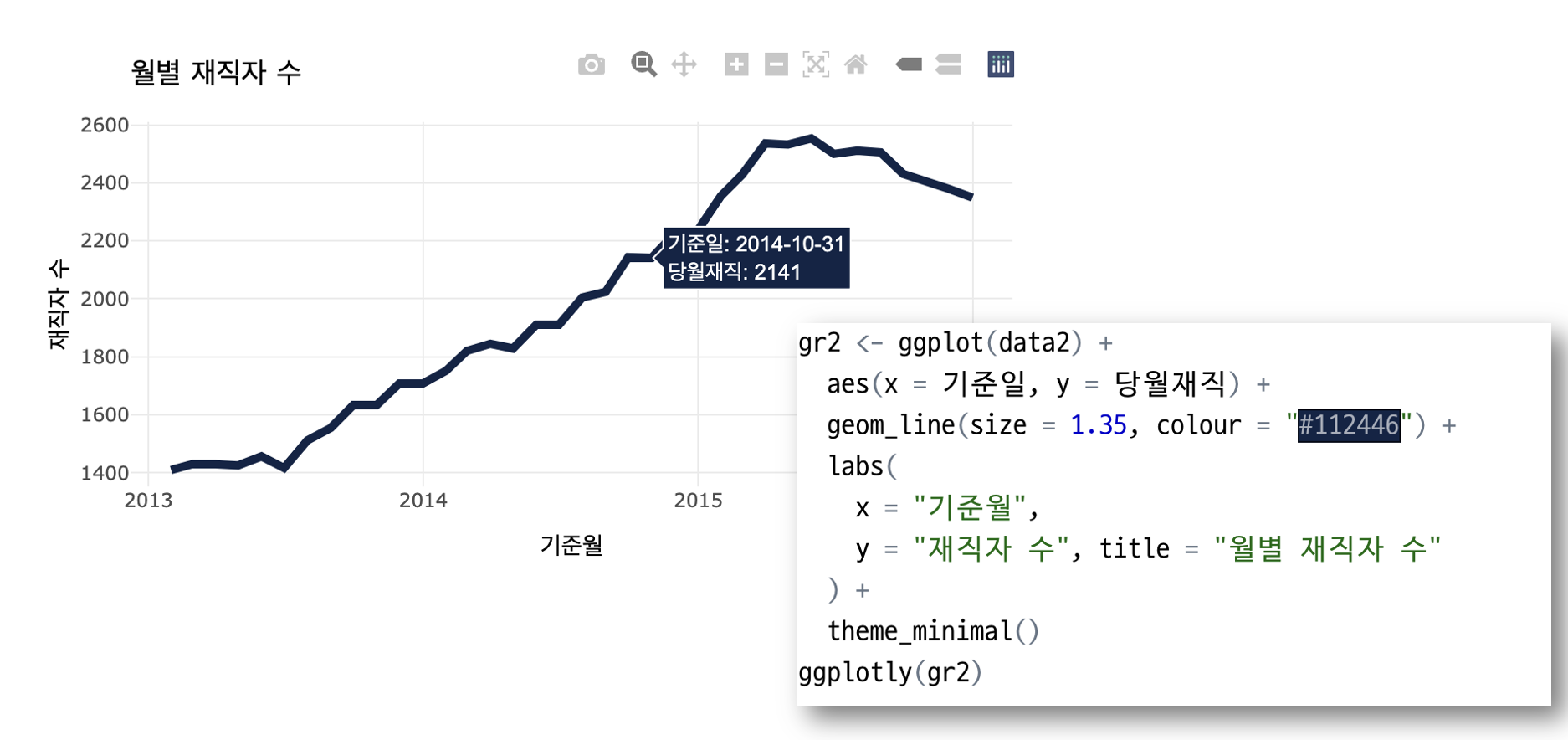
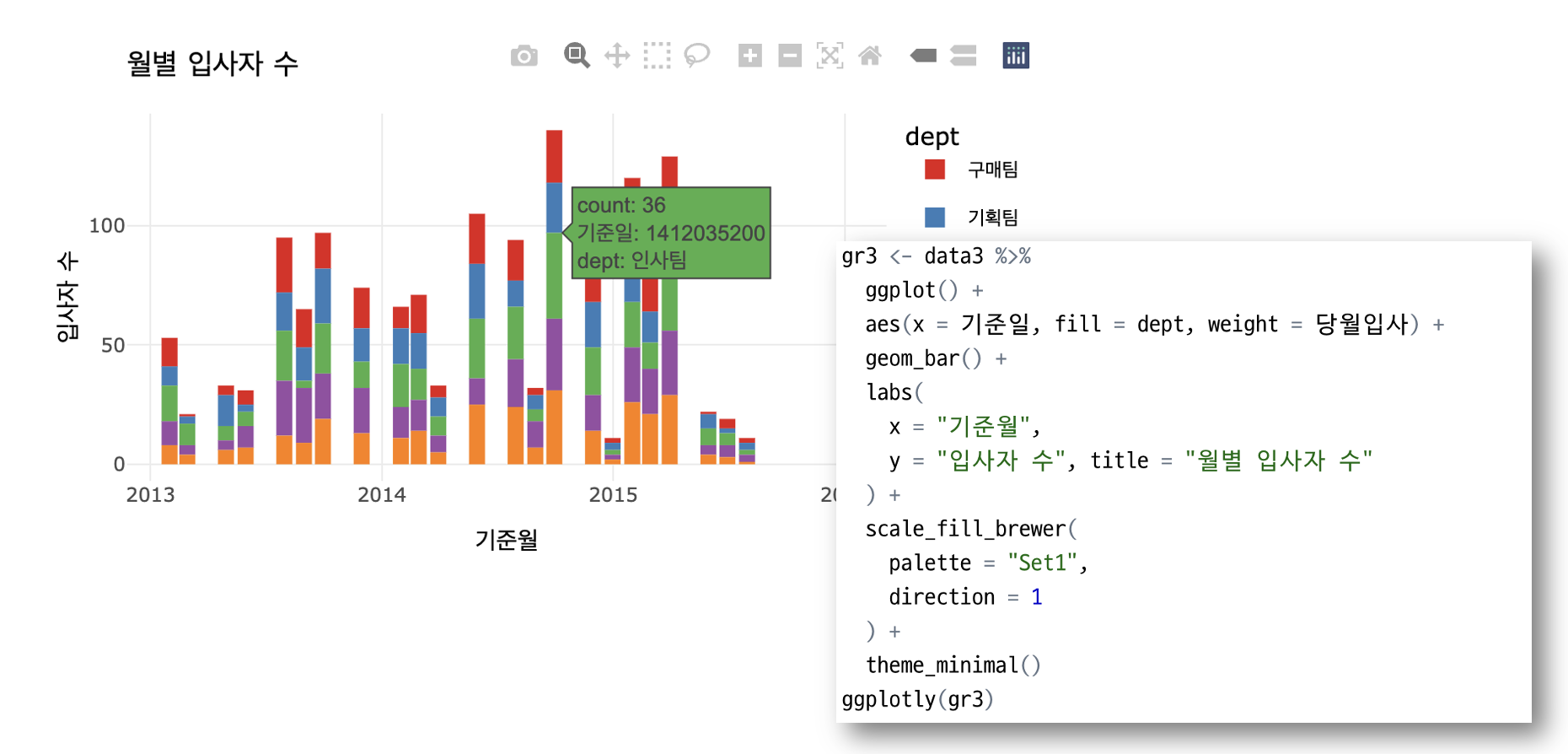
BCD 대리 "팀장님, 최근 n년간부서별입사자/재직자/퇴직자 수 변화를월별로 보고드립니다."
마치며...
다시 한번 느끼지만, 세상에 쉬운게 없다.
'People Insight' 카테고리의 다른 글
| 코멘트 유사도를 활용한 조직 네트워크 분석(Organizational Network Analysis) (0) | 2023.04.09 |
|---|---|
| LDA Topic Modeling을 활용한 기업 리뷰 분석 (0) | 2023.04.08 |
| R을 활용한 채용 성과 및 업무적합성 분석과 시각화 (0) | 2023.03.25 |
| 상관관계 분석을 사용한 채용 경로 대시보드 구축과 효율성 파악 (0) | 2023.03.25 |
| 채용 및 면접 진행상황을 데이터를 통해 보고하는 방법 (0) | 2023.03.25 |



