
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- 성장혼합모형
- HR Anlaytics
- people analytics
- HR Analytics
- HR대시보드
- HR 애널리틱스
- 유사도분석
- 다항로지스틱회귀분석
- PA 미래
- survival analytics
- 데이터분석
- 피플 애널리틱스
- 채용 대시보드
- 인사데이터
- 회귀분석
- ChatGPT
- Text mining
- 태그도 많이 치는거 힘들다..
- HR데이터
- 하나만 쓰자..
- PA201
- HR 데이터 분석
- Jobplanet
- Workforce Analytics
- LDA Topic Modeling
- HR
- 자기소개서 스크리닝
- Talent Analytics
- HRA
- Pa
- Today
- Total
People-Analytics201
LDA Topic Modeling을 활용한 기업 리뷰 분석 본문
1. 서론
기업에서 사람을 채용할 때, 이력서를 받고 면접을 보는 것과 같이 구직자를 평가하는 만큼,
구직자도 회사에 이력서를 낼 때, 해당 회사에 대한 충분한 정보를 가지고 지원을 합니다.
그럼, 구직자는 회사에 대한 정보를 어디서 얻을까요?
요즘 대부분의 사람들은 “잡플래닛”과 “블라인드”의 기업 리뷰를 볼 것입니다.
그 중에서도 본 포스팅에서는 “잡플래닛” 리뷰에 주목합니다.
바야흐로 대퇴사/대이직시대라고 불리우는 요즘, 모든 직장인들은 이직의 꿈을 가슴에 품고 직장을 다닙니다.
구직자 및 언제든 회사를 떠날 생각을 가지고 있는 현직자들은,
자신에게 맞는 채용 공고에 지원하기 위해 각종 채용 정보와 잡플래닛 리뷰를 수시로 들여다 봅니다.
잡플래닛에 있는 모든 회사 리뷰를 보기 위해서는 프리미엄 회원으로 가입하거나,
현재 재직중인 자사의 리뷰를 무조건 1개는 작성해야 합니다.
그렇기 때문에, 대부분의 현직자는 본인이 다니는 회사의 리뷰를 열심히 작성합니다.
그렇게 쌓인 잡플래닛 리뷰 데이터는 2021년 말 기준 700만 건 정도로 추정하고 있으며,
데이터가 쌓이는 속도는 점차 빨라지고 있습니다.

서론은 여기까지 하고, 기업에서는 채용이 어려운 시기에 적합한 지원자 한 명이라도 더 Sourcing 하기 위해,
혹은 조직문화 개선 요소 도출을 위해, 기업의 HR 담당자들에게도 잡플래닛 리뷰는 관심 분석 대상이 되었습니다.
본 포스팅에서는 이러한 잡플래닛 리뷰를 크롤링을 통해 수집하고,
LDA Topic Modeling이라는 자연어처리(NLP) 기법을 통해 리뷰를 분석하는 방법을 알아봅니다.
Tool은 Python의 Jupyter Notebook을 사용합니다.
2. LDA 토픽모델링이란?
토픽 모델링(Topic Modeling)이란, 방대한 양의 문서로부터 문서로부터 토픽(주제어)을 추출하기 위한 확률 모델의 한 기법으로(Guo , Barnes, & Jia, 2017), 각 문서를 토픽과 단어의 집합으로 가정하고, 해당 문서 내 토픽과 그 토픽을 구성하는 단어의 중요도를 확률적으로 제시하는 방법입니다(안병대, 신동원 & 이한준, 2022).

잠재 디리클레 할당(Latent Dirichlet Allocation, LDA) 기법은 토픽 모델링에서 범용되는 기법으로, 기존 LSI, pLSI 토픽 모델링과는 달리 비구조적인 문서에 대하여 각 문서에 어떤 주제들이 존재하는지를 서술하는 확률에 기반한 토픽 모델링 기법입니다.
각 문서는 주요 통계적 관계를 보존하면서, 말뭉치(Corpus)의 효율적인 연산을 위해 구성 요소들에 대한 최적의 주제를 찾습니다(Blei, Ng, & Jordan, 2003).

LDA는 디리클레 확률 기반의 토픽 모델링을 통해 문서 내에서 어떤 토픽들이 어떠한 비율로 구성되어 있는지를 나타내어 주며(Blei et al, 2003), 대량의 문서 데이터를 체계적이고 통계적으로 요약함으로써 텍스트 문서 집합을 숫자로 이루어진 토픽과 단어의 벡터 집합으로 변환시켜주기 때문에 최근 온라인 기업리뷰를 분석하는 연구에 많이 활용되고 있습니다(안병대 등, 2022).
3. 잡플래닛 리뷰 크롤링
크롤링은 Python의 BeautifulSoup 크롤링 패키지를 활용하였습니다.
크롤링 코드는 https://makes-sense.tistory.com/m/8 를 활용하였으니 참고 부탁드립니다.
Jobplanet 기업리뷰 크롤링코드
잡플래닛에 있는 기업별 리뷰페이지들을 크롤링해서 엑셀로 만들어주는 코드입니다. import requests from bs4 import BeautifulSoup import pandas as pd import re login_url = 'https://www.jobplanet.co.kr/users/sign_in' #email 본
makes-sense.tistory.com
import requests
from bs4 import BeautifulSoup
import pandas as pd
import re
login_url = '<https://www.jobplanet.co.kr/users/sign_in>'
# email에 본인 잡플래닛 아이디, password 본인 패스워드 입력
# 단, 리뷰를 남겨서 전체 접근이 가능한 상태여야함
email = 'abc@gmail.com'
password = 'abc123'
LOGIN_INFO ={
'user[email]' : email,
'user[password]' : password,
'commit' : '로그인'
}
session = requests.session()
res = session.post(login_url, data = LOGIN_INFO, verify = False)
res.raise_for_status()
result = []
def clean_str(text):
pattern = '([ㄱ-ㅎㅏ-ㅣ]+)' # 한글 자음, 모음 제거
text = re.sub(pattern=pattern, repl='', string=text)
pattern = '<[^>]*>' # HTML 태그 제거
text = re.sub(pattern=pattern, repl='', string=text)
pattern = '[^\\w\\s]' # 특수기호제거
text = re.sub(pattern=pattern, repl='', string=text)
text = text.replace('\\r','. ')
return text
#url 은 보고싶은 기업의 리뷰 URL이며 마지막은 ?page= 형태로 해야함. last_page는 해당 기업 리뷰의 마지막 페이지 입력
last_page = 1670
for idx in range(1,last_page):
url = '<https://www.jobplanet.co.kr/companies/30139/reviews/%EC%82%BC%EC%84%B1%EC%A0%84%EC%9E%90?page='+str(idx)>
res = session.get(url)
res.raise_for_status()
soup = BeautifulSoup(res.text, 'html.parser')
count3 = 0
count4 = 0
count5 = 0
try:
for k in range(5):
reviewer_info = []
# 응답자 정보
position = soup.select('.content_top_ty2 > span.txt1')[0 + count4].text
status = soup.select('.content_top_ty2 > span.txt1')[1 + count4].text
loc = soup.select('.content_top_ty2 > span.txt1')[2 + count4].text
day = soup.select('.content_top_ty2 > span.txt1')[3+ count4].text
# 점
star_rating = soup.select('.us_star_m > div.star_score')[0+k]['style'][6:-1]
# rating 5*5
promotion = soup.select('.bl_score')[0 + count5]['style'][6:-1]
welfare = soup.select('.bl_score')[1 + count5]['style'][6:-1]
balance = soup.select('.bl_score')[2 + count5]['style'][6:-1]
culture = soup.select('.bl_score')[3 + count5]['style'][6:-1]
top = soup.select('.bl_score')[4 + count5]['style'][6:-1]
# 중심 제목
content = soup.select('h2.us_label')[0+k].text
# 장단점 경영진 의견
merit = soup.select('dl.tc_list > dd.df1 > span')[0 + count3].text
disadvantages = soup.select('dl.tc_list > dd.df1 > span')[1 + count3].text
df_tit = soup.select('dl.tc_list > dd.df1 > span')[2 + count3].text
reviewer_info = [position, status, loc, day, star_rating, promotion, welfare, balance, culture, top,clean_str(content),clean_str(merit),clean_str(disadvantages), clean_str(df_tit)]
result.append(reviewer_info)
reviewer_info=[]
count3 += 3
count4 += 4
count5 += 5
print("pass :"+str(idx)+"-"+str(k))
except :
print("fail :" + str(idx))
pass
colname = ['직무','상황','지역','작성일','총점','승진 기회 및 가능성','복지 및 급여','업무와 삶의 균형','사내문화','경영진','총평','장점','단점','바라는점']
df = pd.DataFrame(result,columns=colname)
#저장을 희망하는 파일명으로 저장
df.to_excel("jobplanet_삼성전자.xlsx")
print(result)
본 포스팅에서는 시가총액 기준 상위 404개의 기업 리뷰 약 10만 4천 건을 크롤링하였습니다.
각 HR 담당자께서는 본인 소속 회사 및 동종업계, 계열사 등의 리뷰 데이터를 수집할 수 있겠습니다.
4. LDA Topic Modeling
이렇게 크롤링 하여 수집한 잡플래닛 리뷰를 LDA 토픽모델링을 통해 분석하고, pyLDAvis 시각화 패키지를 활용해 시각화까지 진행해보았습니다. LDA 토픽모델링 코드는 아래 “앱 리뷰 분석 프로젝트”의 포스팅의 코드를 참고하여 분석을 진행했습니다.
[NLP] LDA 토픽 모델링을 활용한 앱 리뷰 분석 프로젝트
📚 목차 1. 개요 2. 데이터셋 3. LDA 토픽 모델링 개념 4. LDA 토픽 모델링 시각화 5. 전체 코드 6. 코드 설명 7. 결과 해석방법 8. 인사이트 도출 1. 개요 본 프로젝트에서는 건강관리 앱 리뷰 텍스트마
heytech.tistory.com
해당 코드를 활용하기 위해서는 Mecab 형태소 분석기의 사전 설치가 필요합니다.
(Mecab은 현재 한국어 형태소 분석기 중 가장 성능이 좋다고 알려져 있는 형태소 분석기입니다.)
최적의 토픽 갯수(Number of Topic)는 연구자가 지정해야 할 Hyperparameter로서,
본 포스팅에서는 일관성 지표(Coherence Score)를 산출하여 최적의 토픽 갯수를 선정하였습니다.
4. 1 "장점" 리뷰 분석
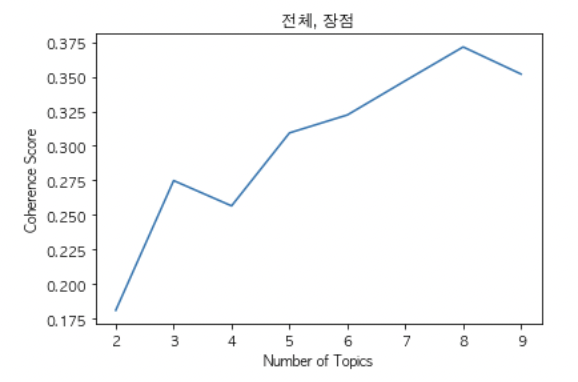
Number of Topics가 8일 때, Coherence Score가 높은 것을 확인할 수 있습니다.
따라서 “장점” 리뷰는 최적의 Topic 갯수는 8로 지정하여 LDA Topic Modeling을 진행합니다.
아래는 “장점”에 대한 LDA Topic Modeling 결과입니다.
| No | Topic | word_prop |
| 1 | 보상 (급/상여금 등) |
0.084*"월급" + 0.065*"돈" + 0.055*"지원" + 0.033*"수당" + 0.029*"복지" + 0.028*"지급" + 0.025*"장점" + 0.019*"윗사람" + 0.017*"상여금" + 0.014*"명절" |
| 2 | 근무환경1 (근무 위치) |
0.139*"업무" + 0.075*"근무" + 0.047*"강도" + 0.035*"환경" + 0.031*"초봉" + 0.027*"위치" + 0.023*"서울" + 0.019*"본사" + 0.018*"가능" + 0.016*"장점" |
| 3 | 근무환경2 (기숙사, 식당, 통근버스 등) |
0.059*"제공" + 0.033*"점심" + 0.026*"식당" + 0.025*"복지" + 0.023*"회사" + 0.022*"지원" + 0.021*"기숙사" + 0.019*"버스" + 0.018*"저녁" + 0.018*"사내" |
| 4 | 일과 삶의 균형 (연차, 야근 등) |
0.134*"연차" + 0.083*"자유" + 0.075*"사용" + 0.068*"가능" + 0.063*"눈치" + 0.040*"퇴근" + 0.038*"휴가" + 0.030*"야근" + 0.028*"출퇴근" + 0.021*"근무" |
| 5 | 영업환경 (매출 압박 등) |
0.101*"사람" + 0.044*"회사" + 0.028*"영업" + 0.021*"사원" + 0.020*"중견" + 0.019*"매출" + 0.018*"신입" + 0.016*"장점" + 0.014*"이상" + 0.013*"압박" |
| 6 | 성장 가능성 (매출 규모, 경험 기회) |
0.087*"회사" + 0.039*"안정" + 0.033*"기업" + 0.022*"사업" + 0.021*"가능" + 0.021*"성장" + 0.020*"교육" + 0.018*"기회" + 0.016*"경험" + 0.016*"규모" |
| 7 | 조직문화 (수평적 조직문화) |
0.112*"분위기" + 0.066*"문화" + 0.034*"부서" + 0.032*"사람" + 0.031*"직원" + 0.025*"회사" + 0.024*"기업" + 0.022*"수평" + 0.019*"조직" + 0.019*"업무" |
| 8 | 동종업계 대비 우수 (급여, 복지 등) |
0.089*"연봉" + 0.075*"복지" + 0.074*"기업" + 0.043*"업계" + 0.035*"급여" + 0.034*"회사" + 0.034*"장점" + 0.026*"수준" + 0.020*"대비" + 0.018*"동종" |
word_prop에는 각 토픽에서 함께 언급되는 Keyword와, 구성하고 있는 비율이 나타납니다.
위와 같이 각 토픽의 word_prop를 참고하여, 주제를 적절하게 설정해주면 됩니다.
개인적으로 눈에 띄는 토픽은 3번 근무환경(기숙사, 구내식당, 통근버스)과
6번 기업의 성장가능성 (매출 규모, 다양한 경험 가능, 성장지원체계 등) 이네요.
pyLDAvis로 시각화 한 결과는 아래와 같습니다.
https://y-u-p.github.io/LDA-Topic-Modeling/1.html
4. 2 단점 리뷰 분석

Number of Topics가 9일 때, Coherence Score가 높은 것을 확인할 수 있습니다.
따라서 “단점” 리뷰는 최적의 Topic 갯수는 9로 지정하여 LDA Topic Modeling을 진행합니다.
아래는 “단점”에 대한 LDA Topic Modeling 결과입니다.
| No | Topic | word_prop |
| 1 | 업무강도 | 0.157*"업무" + 0.073*"부서" + 0.059*"야근" + 0.028*"강도" + 0.018*"체계" + 0.016*"수당" + 0.015*"경우" + 0.015*"교육" + 0.013*"차이" + 0.013*"처리" |
| 2 | 의사결정 체계 (보고, 문서, 회의) |
0.081*"보고" + 0.063*"업무" + 0.040*"작업" + 0.039*"회의" + 0.035*"효율" + 0.031*"결정" + 0.028*"단순" + 0.028*"문서" + 0.025*"제품" + 0.021*"필요" |
| 3 | 사람 | 0.119*"사람" + 0.034*"출근" + 0.034*"퇴근" + 0.033*"회사" + 0.027*"영업" + 0.020*"사원" + 0.019*"신입" + 0.018*"직원" + 0.014*"퇴사" + 0.013*"생각" |
| 4 | 보수적인 조직문화 (군대식, 꼰대) |
0.136*"문화" + 0.066*"보수" + 0.062*"분위기" + 0.040*"기업" + 0.035*"수직" + 0.035*"꼰대" + 0.032*"회사" + 0.032*"군대" + 0.030*"조직" + 0.022*"군대식" |
| 5 | 합리적인 인사평가 | 0.042*"회사" + 0.032*"인사" + 0.019*"직원" + 0.019*"평가" + 0.019*"임원" + 0.015*"영업" + 0.013*"매출" + 0.013*"오너" + 0.013*"경영" + 0.012*"운영" |
| 6 | 직급 및 승진체계 | 0.055*"근무" + 0.055*"승진" + 0.039*"환경" + 0.035*"공장" + 0.022*"부장" + 0.022*"직급" + 0.021*"진급" + 0.020*"본사" + 0.016*"대리" + 0.016*"불편" |
| 7 | 발전 가능성(성장동력) | 0.050*"회사" + 0.026*"발전" + 0.025*"성장" + 0.024*"부족" + 0.023*"사업" + 0.019*"가능" + 0.019*"직원" + 0.017*"사람" + 0.016*"개발" + 0.014*"기업" |
| 8 | 생산직, 비정규직 차별 | 0.045*"연차" + 0.043*"현장" + 0.031*"근무" + 0.026*"비정규직" + 0.025*"사용" + 0.023*"정규직" + 0.022*"눈치" + 0.021*"생산" + 0.015*"휴가" + 0.015*"차별" |
| 9 | 급여 및 복지 | 0.102*"연봉" + 0.063*"복지" + 0.037*"급여" + 0.031*"단점" + 0.031*"회사" + 0.027*"기업" + 0.022*"수준" + 0.021*"업계" + 0.021*"직원" + 0.018*"생각" |
여기서는 개인적으로 눈에 띄는 토픽은, 8번 “생산직과 비정규직에 대한 차별”이네요.
정규직과의 차별과 현장 근무(생산직)에 대한 내용들이 단점으로 언급되고 있는 것을 확인할 수 있습니다.
pyLDAvis로 시각화 한 결과는 아래와 같습니다.
https://y-u-p.github.io/LDA-Topic-Modeling/2.html
4. 3 경영진에 바라는 점 리뷰 분석

Number of Topics가 8일 때, Coherence Score가 높은 것을 확인할 수 있습니다.
따라서 “경영진에 바라는 점” 리뷰는 최적의 Topic 갯수는 8로 지정하여 LDA Topic Modeling을 진행합니다.
아래는 “경영진에 바라는 점”에 대한 LDA Topic Modeling 결과입니다.
| No | Topic | word_prop |
| 1 | 비정규직 전환 요구 | 0.090*"사원" + 0.061*"신입" + 0.038*"채용" + 0.035*"비정규직" + 0.033*"월급" + 0.031*"정규직"+ 0.027*"기회" + 0.018*"전환" + 0.016*"마케팅" + 0.014*"차별" |
| 2 | 급여 및 보상 | 0.124*"직원" + 0.106*"복지" + 0.047*"신경" + 0.041*"연봉" + 0.035*"개선" + 0.029*"체계" + 0.027*"보상" + 0.026*"급여" + 0.026*"근무" + 0.025*"필요" |
| 3 | 인력 충원 및 교육 | 0.108*"사람" + 0.089*"업무" + 0.052*"필요" + 0.028*"영업" + 0.024*"인력" + 0.022*"생각" + 0.22*"인원" + 0.021*"부서" + 0.021*"관리" + 0.020*"교육" |
| 4 | 합리적인 인사평가 | 0.057*"경영" + 0.037*"인사" + 0.029*"평가" + 0.025*"필요" + 0.023*"제품" + 0.018*"성과" + 0.016*"장기" + 0.016*"전문" + 0.014*"운영" + 0.012*"제도" |
| 5 | 성장지원체계 마련 | 0.146*"회사" + 0.086*"직원" + 0.075*"생각" + 0.035*"발전" + 0.022*"성장" + 0.022*"퇴사" + 0.021*"기업" + 0.018*"경영진" + 0.015*"인재" + 0.012*"임원" |
| 6 | 성장동력 확보 | 0.086*"사업" + 0.084*"투자" + 0.046*"신규" + 0.044*"직원" + 0.041*"필요" + 0.039*"적극" + 0.029*"개발" + 0.024*"불만" + 0.020*"추진" + 0.019*"미래" |
| 7 | 조직문화 개선 | 0.103*"문화" + 0.056*"필요" + 0.048*"개선" + 0.048*"기업" + 0.032*"조직" + 0.028*"변화" + 0.023*"혁신" + 0.020*"군대" + 0.020*"분위기" + 0.019*"사내" |
| 8 | 경영진 인식개선 | 0.052*"경영진" + 0.039*"회사" + 0.032*"현장" + 0.030*"분위기" + 0.030*"사람" + 0.023*"결정" + 0.017*"개인" + 0.016*"의사" + 0.015*"지금" + 0.013*"눈치" |
개인적으로 눈에 띄는 토픽은 1번 “비정규직 전환 요구”와 6번 “성장동력 확보” 였습니다. 계약기간이 만료되는 비정규직에 대한 정직원 전환 기회 및 차별 철폐 등에 대한 요구와, 회사와 직원의 발전을 위해 신사업, 미래에 투자하는 등 성장동력 확보를 경영진에 요구하고 있는 것을 확인할 수 있습니다.
pyLDAvis로 시각화 한 결과는 아래와 같습니다.
https://y-u-p.github.io/LDA-Topic-Modeling/3.html
5. 마무리하며
본 포스팅에서는 기업의 잡플래닛 리뷰를 장점, 단점, 경영진에 바라는 점으로 나누어
토픽 모델링 분석을 통해 다량의 비정형(텍스트) 데이터의 토픽을 추출해보았습니다.
LDA Topic Modeling에서는 토픽의 갯수 (Number of Topics)는 연구자가 지정해야 하는 Hyperparameter입니다.
따라서 최적의 토픽 갯수 산출을 위해 Coherence Score와 Perplexity 산정 등 객관적인 지표를 반드시 뒷받침 해야합니다.
또한, word_prop를 참고하여 토픽을 정하는 것 또한 오롯이 연구자의 몫입니다.
따라서 word_prop를 적절하게 해석하여 토픽을 설정하고,
데이터 기반 HR 의사결정을 이끌어 내기 위한 Storytelling을 만들어 내는 것 역시
HR Analytics 담당자에게 요구되는 역량이라 할 수 있습니다.
본 포스팅에서 실시한 분석 역시,
그러한 점에서는 한계점을 가진 완벽하지 못한 분석이라 할 수 있습니다.
더 나은 텍스트 분석 기법과, 텍스트 데이터를 다루는 법에 대한 아이디어가 있다면 언제든 지적과 의견 제안 부탁드립니다.
Reference
- Guo, Y., Barnes, S. J., & Jia, Q. (2017). Mining meaning from online ratings and reviews: Tourist satisfaction analysis using latent dirichlet allocation. Tourism management, 59, 467-483.
- 안병대, 신동원, & 이한준. (2022). 동기ㆍ위생이론에 근거한 직무만족 및 불만족요인에 관한 연구-토픽모델링과 잡플래닛 기업리뷰를 활용하여. 경영과 정보연구, 41(1), 39-56.
- Blei, D. M., Ng, A. Y., & Jordan, M. I. (2003). Latent dirichlet allocation. Journal of machine Learning research, 3(Jan), 993-1022.
- Jobplanet 기업리뷰 크롤링코드 https://makes-sense.tistory.com/m/8
- [NLP] LDA 토픽 모델링을 활용한 앱 리뷰 분석 프로젝트 https://heytech.tistory.com/401
[NLP] LDA 토픽 모델링을 활용한 앱 리뷰 분석 프로젝트
📚 목차 1. 개요 2. 데이터셋 3. LDA 토픽 모델링 개념 4. LDA 토픽 모델링 시각화 5. 전체 코드 6. 코드 설명 7. 결과 해석방법 8. 인사이트 도출 1. 개요 본 프로젝트에서는 건강관리 앱 리뷰 텍스트마
heytech.tistory.com
Jobplanet 기업리뷰 크롤링코드
잡플래닛에 있는 기업별 리뷰페이지들을 크롤링해서 엑셀로 만들어주는 코드입니다. import requests from bs4 import BeautifulSoup import pandas as pd import re login_url = 'https://www.jobplanet.co.kr/users/sign_in' #email 본
makes-sense.tistory.com
'People Insight' 카테고리의 다른 글
| 코린이도 한다, 텍스트 크롤링 (feat. ChatGPT, 구글링) (0) | 2023.04.09 |
|---|---|
| 코멘트 유사도를 활용한 조직 네트워크 분석(Organizational Network Analysis) (0) | 2023.04.09 |
| 최근 N년간 부서별 입사자/재직자/퇴직자 수 계산하기 (0) | 2023.03.26 |
| R을 활용한 채용 성과 및 업무적합성 분석과 시각화 (0) | 2023.03.25 |
| 상관관계 분석을 사용한 채용 경로 대시보드 구축과 효율성 파악 (0) | 2023.03.25 |



